
Was ist Textanmerkung beim maschinellen Lernen?
Textanmerkungen beim maschinellen Lernen beziehen sich auf das Hinzufügen von Metadaten oder Beschriftungen zu Rohtextdaten, um strukturierte Datensätze zum Trainieren, Bewerten und Verbessern von Modellen für maschinelles Lernen zu erstellen. Dies ist ein entscheidender Schritt bei Aufgaben der Verarbeitung natürlicher Sprache (NLP), da er Algorithmen dabei hilft, Texteingaben zu verstehen, zu interpretieren und Vorhersagen zu treffen.
Textanmerkungen sind wichtig, da sie dazu beitragen, die Lücke zwischen unstrukturierten Textdaten und strukturierten, maschinenlesbaren Daten zu schließen. Dies ermöglicht es Modellen des maschinellen Lernens, Muster aus den annotierten Beispielen zu lernen und zu verallgemeinern.
Hochwertige Anmerkungen sind für die Erstellung genauer und robuster Modelle von entscheidender Bedeutung. Aus diesem Grund ist bei der Textanmerkung eine sorgfältige Beachtung von Details, Konsistenz und Fachwissen unerlässlich.
Arten von Textanmerkungen

Beim Training von NLP-Algorithmen ist es wichtig, über große annotierte Textdatensätze zu verfügen, die auf die individuellen Anforderungen jedes Projekts zugeschnitten sind. Für Entwickler, die solche Datensätze erstellen möchten, finden Sie hier eine einfache Übersicht über fünf beliebte Textanmerkungstypen.

Stimmungsanmerkung
Sentiment-Annotationen identifizieren die einem Text zugrunde liegenden Emotionen, Meinungen oder Einstellungen. Annotatoren kennzeichnen Textsegmente mit positiven, negativen oder neutralen Sentiment-Tags. Die Stimmungsanalyse, eine Schlüsselanwendung dieses Annotationstyps, wird häufig in der Überwachung sozialer Medien, der Analyse von Kundenfeedback und der Marktforschung eingesetzt.
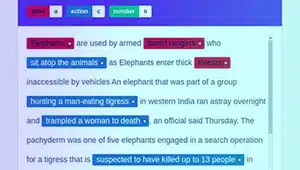
Absichtsanmerkung
Absichtsanmerkungen zielen darauf ab, den Zweck oder das Ziel eines bestimmten Textes zu erfassen. Bei dieser Art von Annotation weisen Annotatoren Textsegmenten Beschriftungen zu, die bestimmte Benutzerabsichten repräsentieren, z. B. das Anfordern von Informationen, das Anfordern von etwas oder das Ausdrücken einer Präferenz.
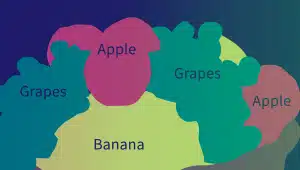
Semantische Annotation
Semantische Annotationen identifizieren die Bedeutung und Beziehungen zwischen Wörtern, Phrasen und Sätzen. Annotatoren verwenden verschiedene Techniken wie Textsegmentierung, Dokumentanalyse und Textextraktion, um die semantischen Eigenschaften von Textelementen zu kennzeichnen und zu klassifizieren.

Entitätsanmerkung
Entitätsanmerkungen sind bei der Erstellung von Chatbot-Trainingsdatensätzen und anderen NLP-Daten von entscheidender Bedeutung. Dabei geht es darum, Entitäten im Text zu finden und zu kennzeichnen. Zu den Arten von Entitätsanmerkungen gehören:

Sprachliche Anmerkung
Die linguistische Annotation befasst sich mit den strukturellen und grammatikalischen Aspekten der Sprache. Es umfasst verschiedene Unteraufgaben, wie z. B. Wortart-Tagging, syntaktisches Parsen und morphologische Analyse.

Versicherungen
Mithilfe von Textanmerkungen können Versicherungsunternehmen Kundenfeedback analysieren, Schadensfälle bearbeiten und Betrug erkennen. Durch den Einsatz von KI-Modellen, die auf annotierten Datensätzen trainiert wurden, können Versicherer:

Bankinggg
Textanmerkungen ermöglichen einen verbesserten Kundenservice, Betrugserkennung und Dokumentenanalyse im Bankwesen. Auf annotierten Daten trainierte KI-Systeme können:

Telecom
Textanmerkungen ermöglichen es Telekommunikationsunternehmen, den Kundensupport zu verbessern, soziale Medien zu überwachen und Netzwerkprobleme zu verwalten. Modelle des maschinellen Lernens, die auf annotierten Datensätzen trainiert werden, können:
Wie kommentiere ich Textdaten?
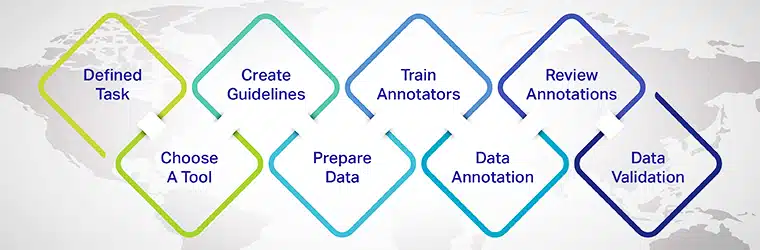
- Definieren Sie die Anmerkungsaufgabe: Bestimmen Sie die spezifische NLP-Aufgabe, die Sie angehen möchten, z. B. Stimmungsanalyse, Erkennung benannter Entitäten oder Textklassifizierung.
- Wählen Sie ein geeignetes Anmerkungstool: Wählen Sie ein Textanmerkungstool oder eine Plattform aus, die Ihren Projektanforderungen entspricht und die gewünschten Anmerkungstypen unterstützt.
- Erstellen Sie Anmerkungsrichtlinien: Entwickeln Sie klare und konsistente Richtlinien, die Annotatoren befolgen müssen, um qualitativ hochwertige und genaue Anmerkungen sicherzustellen.
- Wählen Sie die Daten aus und bereiten Sie sie vor: Sammeln Sie eine vielfältige und repräsentative Stichprobe von Rohtextdaten, an denen die Kommentatoren arbeiten können.
- Trainieren und bewerten Sie Kommentatoren: Bereitstellung von Schulungen und kontinuierlichem Feedback für Annotatoren, um Konsistenz und Qualität im Annotationsprozess sicherzustellen.
- Kommentieren Sie die Daten: Annotatoren beschriften den Text gemäß den definierten Richtlinien und Annotationstypen.
- Überprüfen und verfeinern Sie Anmerkungen: Überprüfen und verfeinern Sie die Anmerkungen regelmäßig, beheben Sie etwaige Inkonsistenzen oder Fehler und verbessern Sie den Datensatz iterativ.
- Teilen Sie den Datensatz: Teilen Sie die annotierten Daten in Trainings-, Validierungs- und Testsätze auf, um das Modell für maschinelles Lernen zu trainieren und zu bewerten.
Was kann Shaip für Sie tun?
Shaip bietet maßgeschneiderte Angebote Lösungen für Textanmerkungen um Ihre KI- und maschinellen Lernanwendungen in verschiedenen Branchen voranzutreiben. Mit einem starken Fokus auf qualitativ hochwertige und genaue Anmerkungen kann das erfahrene Team und die fortschrittliche Anmerkungsplattform von Shaip mit unterschiedlichen Textdaten umgehen.
Ob Stimmungsanalyse, Erkennung benannter Entitäten oder Textklassifizierung: Shaip liefert benutzerdefinierte Datensätze, um das Sprachverständnis und die Leistung Ihrer KI-Modelle zu verbessern.
Vertrauen Sie Shaip, wenn es darum geht, Ihren Textanmerkungsprozess zu optimieren und sicherzustellen, dass Ihre KI-Systeme ihr volles Potenzial ausschöpfen.

