
Bild sagt mehr als tausend Worte ist ein ziemlich verbreitetes Sprichwort, das wir alle gehört haben. Nun, wenn ein Bild mehr als tausend Worte sagen könnte, stell dir nur vor, was ein Video sagen könnte? Vielleicht eine Million Dinge. Eines der revolutionären Teilgebiete der künstlichen Intelligenz ist das Computerlernen. Keine der bahnbrechenden Anwendungen, die uns versprochen wurden, wie fahrerlose Autos oder intelligente Kassen im Einzelhandel, ist ohne Videoannotation möglich.
Künstliche Intelligenz wird in mehreren Branchen eingesetzt, um komplexe Projekte zu automatisieren, innovative und fortschrittliche Produkte zu entwickeln und wertvolle Erkenntnisse zu liefern, die die Art des Geschäfts verändern. Computer Vision ist ein solcher Teilbereich der KI, der die Art und Weise, wie mehrere Branchen arbeiten, die von riesigen Mengen an erfassten Bildern und Videos abhängig sind, vollständig verändern kann.
Computer Vision, auch CV genannt, ermöglicht es Computern und verwandten Systemen, aussagekräftige Daten aus visuellen Elementen – Bildern und Videos – zu ziehen und auf der Grundlage dieser Informationen die erforderlichen Maßnahmen zu ergreifen. Modelle für maschinelles Lernen werden darauf trainiert, Muster zu erkennen und diese Informationen in ihrem künstlichen Speicher zu erfassen, um visuelle Echtzeitdaten effektiv zu interpretieren.


Was ist Videoanmerkung?
Videoannotation ist die Technik zum Erkennen, Markieren und Beschriften jedes Objekts in einem Video. Es hilft Maschinen und Computern, sich von Bild zu Bild bewegende Objekte in einem Video zu erkennen.
 Mit einfachen Worten, ein menschlicher Annotator untersucht ein Video, beschriftet das Bild Bild für Bild und stellt es in vordefinierte Kategoriedatensätze zusammen, die zum Trainieren von Algorithmen für maschinelles Lernen verwendet werden. Die visuellen Daten werden durch das Hinzufügen von Tags mit kritischen Informationen zu jedem Videoframe angereichert.
Mit einfachen Worten, ein menschlicher Annotator untersucht ein Video, beschriftet das Bild Bild für Bild und stellt es in vordefinierte Kategoriedatensätze zusammen, die zum Trainieren von Algorithmen für maschinelles Lernen verwendet werden. Die visuellen Daten werden durch das Hinzufügen von Tags mit kritischen Informationen zu jedem Videoframe angereichert.
Ingenieure kompilierten die annotierten Bilder zu Datensätzen unter Vorgabe
Kategorien, um ihre erforderlichen ML-Modelle zu trainieren. Stellen Sie sich vor, Sie trainieren ein Modell, um seine Fähigkeit zu verbessern, Verkehrssignale zu verstehen. Was im Wesentlichen passiert, ist, dass der Algorithmus auf Ground-Truth-Daten trainiert wird, die riesige Mengen an Videos enthalten, die Verkehrssignale zeigen, was dem ML-Modell hilft, die Verkehrsregeln genau vorherzusagen.
Zweck der Videoanmerkung und -beschriftung in ML
Videoannotation wird hauptsächlich zum Erstellen eines Datensatzes für die Entwicklung eines auf visueller Wahrnehmung basierenden KI-Modells verwendet. Kommentierte Videos werden häufig verwendet, um autonome Fahrzeuge zu bauen, die Verkehrszeichen und die Anwesenheit von Fußgängern erkennen, Fahrspurbegrenzungen erkennen und Unfälle aufgrund unvorhersehbaren menschlichen Verhaltens verhindern können. Kommentierte Videos dienen bestimmten Zwecken der Einzelhandelsbranche in Bezug auf kassenfreie Einzelhandelsgeschäfte und die Bereitstellung individueller Produktempfehlungen.
Es wird auch in verwendet medizinische und gesundheitliche Bereiche, insbesondere in der medizinischen KI, zur genauen Krankheitserkennung und Unterstützung bei Operationen. Wissenschaftler nutzen diese Technologie auch, um die Auswirkungen der Solartechnologie auf Vögel zu untersuchen.
Videoannotation hat mehrere reale Anwendungen. Es wird in vielen Branchen eingesetzt, aber die Automobilindustrie nutzt hauptsächlich ihr Potenzial, um autonome Fahrzeugsysteme zu entwickeln. Werfen wir einen genaueren Blick auf den Hauptzweck.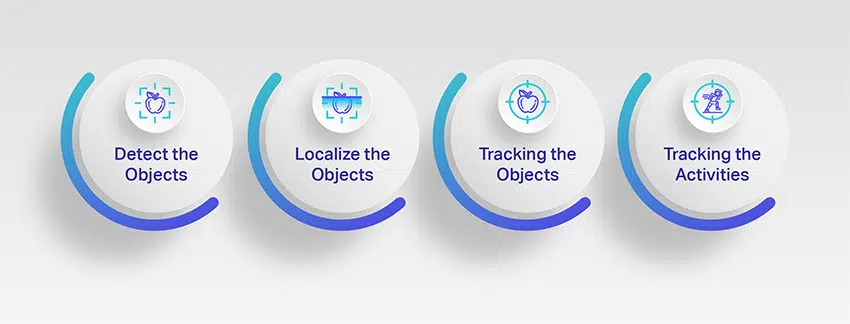
Erkenne die Objekte
Videoannotation hilft Maschinen, in den Videos aufgenommene Objekte zu erkennen. Da Maschinen die Welt um sie herum nicht sehen oder interpretieren können, brauchen sie die Hilfe von Menschen, um die Zielobjekte zu identifizieren und sie in mehreren Einzelbildern genau zu erkennen.
Damit ein maschinelles Lernsystem einwandfrei funktioniert, muss es mit riesigen Datenmengen trainiert werden, um das gewünschte Ergebnis zu erzielen
Lokalisieren Sie die Objekte
Es gibt viele Objekte in einem Video, und das Kommentieren für jedes Objekt ist eine Herausforderung und manchmal unnötig. Objektlokalisierung bedeutet, das sichtbarste Objekt und den wichtigsten Teil des Bildes zu lokalisieren und zu kommentieren.
Verfolgung der Objekte
Videoannotation wird überwiegend beim Bau autonomer Fahrzeuge verwendet, und es ist von entscheidender Bedeutung, über ein Objektverfolgungssystem zu verfügen, das Maschinen hilft, menschliches Verhalten und Straßendynamik genau zu verstehen. Es hilft, den Verkehrsfluss, Fußgängerbewegungen, Fahrspuren, Signale, Verkehrszeichen und mehr zu verfolgen.
Verfolgung der Aktivitäten
Ein weiterer Grund, warum Videokommentare so wichtig sind, ist, dass sie daran gewöhnt sind Computersehen trainieren-basierte ML-Projekte zur genauen Schätzung menschlicher Aktivitäten und Posen. Videokommentare helfen, die Umgebung besser zu verstehen, indem sie menschliche Aktivitäten verfolgen und unvorhersehbares Verhalten analysieren. Darüber hinaus trägt dies auch zur Vermeidung von Unfällen bei, indem die Aktivitäten von nicht statischen Objekten wie Fußgängern, Katzen, Hunden und mehr überwacht und ihre Bewegungen geschätzt werden, um fahrerlose Fahrzeuge zu entwickeln.
Videoanmerkung vs. Bildanmerkung
Video- und Bildkommentare sind sich in vielerlei Hinsicht ziemlich ähnlich, und die Techniken, die zum Kommentieren von Frames verwendet werden, gelten auch für Videokommentare. Es gibt jedoch einige grundlegende Unterschiede zwischen diesen beiden, die Unternehmen bei der Entscheidung für den richtigen Typ helfen werden Datenanmerkung sie für ihren speziellen Zweck benötigen.

Videoannotationstechniken
Bild- und Videoanmerkungen verwenden fast ähnliche Werkzeuge und Techniken, obwohl sie komplexer und arbeitsintensiver sind. Im Gegensatz zu einem einzelnen Bild ist ein Video schwer zu kommentieren, da es fast 60 Bilder pro Sekunde enthalten kann. Das Kommentieren von Videos dauert länger und erfordert auch erweiterte Kommentierungswerkzeuge.
Einzelbildmethode
 Die Einzelbild-Video-Labeling-Methode ist die traditionelle Technik, bei der jedes Bild aus dem Video extrahiert und die Bilder einzeln mit Anmerkungen versehen wird. Das Video ist in mehrere Einzelbilder unterteilt und jedes Bild ist mit herkömmlichen Anmerkungen versehen Bildanmerkung Methode. Beispielsweise wird ein 40-fps-Video in Frames von 2,400 pro Minute zerlegt.
Die Einzelbild-Video-Labeling-Methode ist die traditionelle Technik, bei der jedes Bild aus dem Video extrahiert und die Bilder einzeln mit Anmerkungen versehen wird. Das Video ist in mehrere Einzelbilder unterteilt und jedes Bild ist mit herkömmlichen Anmerkungen versehen Bildanmerkung Methode. Beispielsweise wird ein 40-fps-Video in Frames von 2,400 pro Minute zerlegt.
Die Einzelbildmethode wurde verwendet, bevor Annotator-Tools zum Einsatz kamen. Dies ist jedoch keine effiziente Methode zum Kommentieren von Videos. Diese Methode ist zeitaufwändig und bietet nicht die Vorteile, die ein Video bietet.
Ein weiterer großer Nachteil dieser Methode besteht darin, dass, da das gesamte Video als Sammlung separater Frames betrachtet wird, Fehler bei der Objektidentifikation entstehen. Dasselbe Objekt könnte unter verschiedenen Labels in verschiedenen Frames klassifiziert werden, wodurch der gesamte Prozess an Genauigkeit und Kontext verliert.
Der Zeitaufwand für das Kommentieren von Videos mit der Einzelbildmethode ist außergewöhnlich hoch, was die Kosten des Projekts erhöht. Selbst ein kleineres Projekt mit weniger als 20 fps wird lange zum Kommentieren brauchen. Es könnte viele Fehlklassifizierungsfehler, verpasste Fristen und Anmerkungsfehler geben.
Kontinuierliche Frame-Methode
 Das Continuous-Frame- oder Streaming-Frame-Verfahren ist das beliebtere. Diese Methode verwendet Anmerkungswerkzeuge, die die Objekte im gesamten Video mit ihrer Bild-für-Bild-Position verfolgen. Durch die Verwendung dieser Methode bleiben die Kontinuität und der Kontext gut erhalten.
Das Continuous-Frame- oder Streaming-Frame-Verfahren ist das beliebtere. Diese Methode verwendet Anmerkungswerkzeuge, die die Objekte im gesamten Video mit ihrer Bild-für-Bild-Position verfolgen. Durch die Verwendung dieser Methode bleiben die Kontinuität und der Kontext gut erhalten.
Die kontinuierliche Frame-Methode nutzt Techniken wie den optischen Fluss, um die Pixel in einem Frame und im nächsten präzise zu erfassen und die Bewegung der Pixel im aktuellen Bild zu analysieren. Außerdem wird sichergestellt, dass Objekte im gesamten Video konsistent klassifiziert und beschriftet werden. Die Entität wird auch dann konsistent erkannt, wenn sie sich in den Rahmen hinein und aus diesem heraus bewegt.
Wenn diese Methode zum Kommentieren von Videos verwendet wird, kann das maschinelle Lernprojekt Objekte, die am Anfang des Videos vorhanden sind, genau identifizieren, für einige Frames aus dem Blickfeld verschwinden und wieder auftauchen.
Wenn ein Einzelbildverfahren für die Annotation verwendet wird, könnte der Computer das wiedererscheinte Bild als neues Objekt betrachten, was zu einer Fehlklassifizierung führt. Bei einem kontinuierlichen Frame-Verfahren berücksichtigt der Computer jedoch die Bewegung der Bilder und stellt sicher, dass die Kontinuität und Integrität des Videos gut aufrechterhalten werden.
Die kontinuierliche Frame-Methode ist eine schnellere Methode zum Kommentieren und bietet ML-Projekten mehr Möglichkeiten. Die Annotation ist präzise, eliminiert menschliche Voreingenommenheit und die Kategorisierung ist genauer. Es ist jedoch nicht ohne Risiken. Einige Faktoren, die seine Wirksamkeit beeinträchtigen könnten, wie Bildqualität und Videoauflösung.






Häufige Herausforderungen bei der Videoanmerkung
Videoanmerkungen/-kennzeichnungen können Kommentatoren vor einige Herausforderungen stellen. Schauen wir uns einige Punkte an, die Sie berücksichtigen müssen, bevor Sie beginnen Videoannotation für Computer Vision Projekte.
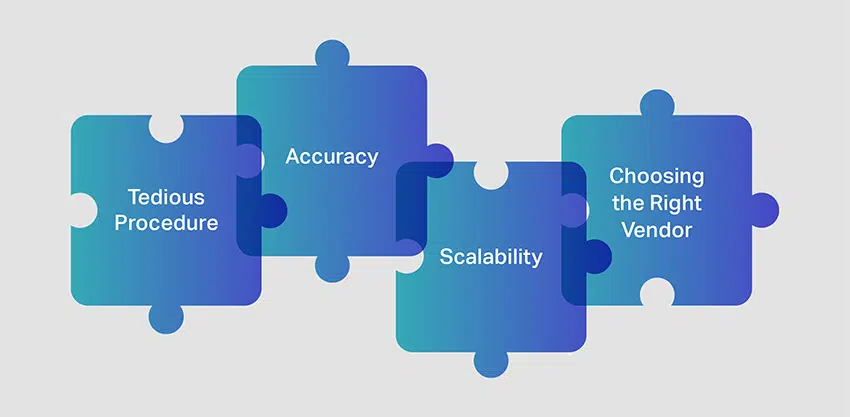
Langwierige Prozedur
Eine der größten Herausforderungen bei der Videoannotation ist der Umgang mit massiven Video-Datensätze die es zu hinterfragen und zu kommentieren gilt. Um die Computer-Vision-Modelle genau zu trainieren, ist es entscheidend, auf große Mengen kommentierter Videos zuzugreifen. Da die Objekte nicht stillstehen, wie dies bei einem Bildkommentierungsprozess der Fall wäre, ist es wichtig, hochqualifizierte Kommentatoren zu haben, die Objekte in Bewegung erfassen können.
Die Videos müssen in kleinere Clips mit mehreren Frames zerlegt werden, und einzelne Objekte können dann für eine genaue Annotation identifiziert werden. Wenn keine Anmerkungswerkzeuge verwendet werden, besteht die Gefahr, dass der gesamte Anmerkungsprozess mühsam und zeitaufwändig wird.
Genauigkeit
Die Aufrechterhaltung eines hohen Genauigkeitsgrades während des Videoannotationsprozesses ist eine herausfordernde Aufgabe. Die Annotationsqualität sollte in jeder Phase konsequent überprüft werden, um sicherzustellen, dass das Objekt korrekt verfolgt, klassifiziert und gekennzeichnet wird.
Wenn die Qualität der Annotation nicht auf verschiedenen Ebenen überprüft wird, ist es unmöglich, einen einzigartigen und qualitativ hochwertigen Algorithmus zu entwerfen oder zu trainieren. Darüber hinaus kann auch eine ungenaue Kategorisierung oder Annotation die Qualität des Vorhersagemodells ernsthaft beeinträchtigen.
Skalierbarkeit
Neben der Sicherstellung von Genauigkeit und Präzision sollte die Videoannotation auch skalierbar sein. Unternehmen bevorzugen Annotationsdienste, die ihnen helfen, ML-Projekte schnell zu entwickeln, bereitzustellen und zu skalieren, ohne das Endergebnis massiv zu beeinträchtigen.
Auswahl des richtigen Anbieters von Videoetiketten
 Die letzte und wahrscheinlich wichtigste Herausforderung bei der Videoannotation besteht darin, die Dienste eines zuverlässigen und erfahrenen Anbieters von Videodatenannotationen in Anspruch zu nehmen. Einen Experten haben Anbieter von Videoanmerkungsdiensten wird einen großen Beitrag leisten, um sicherzustellen, dass Ihre ML-Projekte robust entwickelt und pünktlich bereitgestellt werden.
Die letzte und wahrscheinlich wichtigste Herausforderung bei der Videoannotation besteht darin, die Dienste eines zuverlässigen und erfahrenen Anbieters von Videodatenannotationen in Anspruch zu nehmen. Einen Experten haben Anbieter von Videoanmerkungsdiensten wird einen großen Beitrag leisten, um sicherzustellen, dass Ihre ML-Projekte robust entwickelt und pünktlich bereitgestellt werden.
Es ist auch wichtig, einen Anbieter zu beauftragen, der sicherstellt, dass Sicherheitsstandards und -vorschriften sorgfältig eingehalten werden. Die Wahl des beliebtesten oder günstigsten Anbieters ist nicht immer der richtige Schritt. Sie sollten den richtigen Anbieter auf der Grundlage Ihrer Projektanforderungen, Qualitätsstandards, Erfahrung und Teamkompetenz suchen.