

Textklassifizierung
Der elementarste Ansatz zur Textanmerkung, der sich auf die Kategorisierung von Text basierend auf Inhaltstyp, Absicht, Stimmung und Thema konzentriert. Nach der Kategorisierung werden die Datensätze als Teil eines vordefinierten Segments in das System eingespeist, auf das Maschinen zugreifen können, um eine Antwort zu generieren
Sprachliche Anmerkung
Ursprünglich als Korpusannotation bezeichnet, konzentriert sich diese Form der textuellen Datensatzbeschriftung auf die Sprachdetails von Audio und Texten; Außerdem sind phonetische Annotationen, semantische Annotationen, POS-Tagging usw. erforderlich. Dieser Ansatz ist relevant, wenn es um das Trainieren von Modellen für maschinelle Übersetzung geht

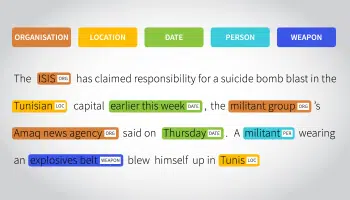
Entitätsanmerkung
Diese Methode der Etikettierung ist entscheidend, wenn es um das Chatbot-Training geht. Der Fokus liegt hier auf dem Extrahieren, Lokalisieren und Markieren von Entitäten, bevor die Daten in das System eingegeben werden. Wie bei jeder Chatbot-basierten Benutzeroberfläche werden Namensentitäten, Schlüsselsätze und POS wie Adjektive, Adverbien und mehr zum Kernstück.

Entitätsverknüpfung
Während Annotatoren Entitäten aus größeren Datenbeständen extrahieren, müssen sie miteinander verknüpft werden, um bedeutungsvolle Datensätze zu bilden. Dies ist eines der wenigen Werkzeuge zur Textannotation, das den Aufbau kompletter Wissensdatenbanken durch Begriffsklärung und schließlich End-to-End-Verknüpfung umfasst. zB URL-Routing, direkt aus dem Chat-Interface

SAO (Subject Action Object)
Wenn ein Text mehrere Entitäten enthält, die durch eine Aktion verknüpft sind. Zum Beispiel ist 'John hits Jimmy' offen für Entity-Annotation und Textklassifizierung, wobei ein Label bezüglich gesetzesbasierter Diskussion hinzugefügt wird. Damit das Modell den Satz jedoch verstehen kann, muss es mit SAO-Daten gefüttert werden, wobei John das Subjekt ist, Jimmy das Objekt und die Klage die Handlung.
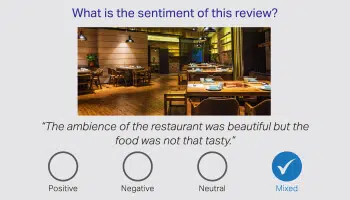
Stimmungsanmerkung
Die Stimmungsannotation kümmert sich um die emotionale Kennzeichnung und ermöglicht es intelligenten Setups, versteckte Konnotationen, Meinungen und bestimmte Gefühle zu erkennen. Annotatoren sind dafür verantwortlich, Text zu überprüfen und ihn als negative, neutrale und positive Stimmungen zu kennzeichnen. Während sich die Intent-Annotation auf den Wunsch der Abfrage konzentriert.

Personen
Engagierte und geschulte Teams:
- 30,000+ Mitarbeiter für Datenerstellung, Kennzeichnung und QA
- Zertifiziertes Projektmanagement-Team
- Erfahrenes Produktentwicklungsteam
- Talentpool-Sourcing- und Onboarding-Team

Prozess
Höchste Prozesseffizienz wird gewährleistet durch:
- Robuster 6-Sigma-Stage-Gate-Prozess
- Ein engagiertes Team von 6 Sigma Black Belts – Key Process Owners & Quality Compliance
- Kontinuierliche Verbesserung und Feedbackschleife

Plattform
Die patentierte Plattform bietet Vorteile:
- Webbasierte End-to-End-Plattform
- Einwandfreie Qualität
- Schnellere TAT
- Nahtlose Lieferung
Personen
Engagierte und geschulte Teams:
- 30,000+ Mitarbeiter für Datenerstellung, Kennzeichnung und QA
- Zertifiziertes Projektmanagement-Team
- Erfahrenes Produktentwicklungsteam
- Talentpool-Sourcing- und Onboarding-Team
Prozess
Höchste Prozesseffizienz wird gewährleistet durch:
- Robuster 6-Sigma-Stage-Gate-Prozess
- Ein engagiertes Team von 6 Sigma Black Belts – Key Process Owners & Quality Compliance
- Kontinuierliche Verbesserung und Feedbackschleife
Plattform
Die patentierte Plattform bietet Vorteile:
- Webbasierte End-to-End-Plattform
- Einwandfreie Qualität
- Schnellere TAT
- Nahtlose Lieferung
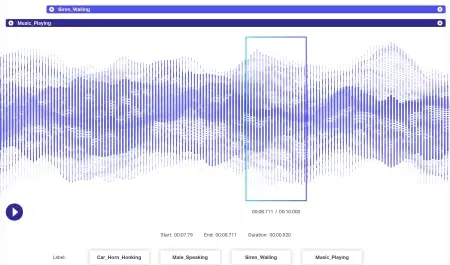
Audiokommentar
Leistungen
Auf die Kennzeichnung von Audioquellen, Sprache und sprachspezifischen Datensätzen über relevante Tools wie Spracherkennung, Sprecherdiarisierung, Emotionserkennung und mehr ist Shaip spezialisiert.

Bildanmerkung
Leistungen
Wir sind stolz darauf, segmentierte Bilddatensätze zu kennzeichnen, um anspruchsvolle Computer-Vision-Modelle zu trainieren. Einige der relevanten Techniken umfassen Grenzerkennung und Bildklassifizierung.

Videoanmerkung
Leistungen
Shaip bietet High-End-Video-Labeling-Services für das Training von Computer Vision-Modellen. Ziel ist es, Datensätze mit Werkzeugen wie Mustererkennung, Objekterkennung und mehr nutzbar zu machen.


