

Was sind große Sprachmodelle?
Large Language Models (LLMs) sind fortschrittliche Systeme der künstlichen Intelligenz (KI), die darauf ausgelegt sind, menschenähnlichen Text zu verarbeiten, zu verstehen und zu generieren. Sie basieren auf Deep-Learning-Techniken und basieren auf riesigen Datensätzen, die normalerweise Milliarden von Wörtern aus verschiedenen Quellen wie Websites, Büchern und Artikeln enthalten. Diese umfassende Ausbildung ermöglicht es LLMs, die Nuancen von Sprache, Grammatik, Kontext und sogar einige Aspekte des Allgemeinwissens zu erfassen.
Einige beliebte LLMs, wie GPT-3 von OpenAI, verwenden eine Art neuronales Netzwerk namens Transformer, das es ihnen ermöglicht, komplexe Sprachaufgaben mit bemerkenswerter Kompetenz zu bewältigen. Diese Modelle können eine Vielzahl von Aufgaben erfüllen, wie zum Beispiel:
- Fragen beantworten
- Zusammenfassender Text
- Sprachen übersetzen
- Inhalte generieren
- Sogar interaktive Gespräche mit Benutzern führen
Während sich LLMs ständig weiterentwickeln, bergen sie ein großes Potenzial für die Verbesserung und Automatisierung verschiedener Anwendungen in allen Branchen, vom Kundenservice und der Inhaltserstellung bis hin zu Bildung und Forschung. Sie werfen jedoch auch ethische und gesellschaftliche Bedenken auf, etwa voreingenommenes Verhalten oder Missbrauch, die im Zuge des technologischen Fortschritts angegangen werden müssen.

Beliebte Beispiele für große Sprachmodelle
Hier sind einige prominente Beispiele für LLMs, die in verschiedenen Branchen weit verbreitet sind:
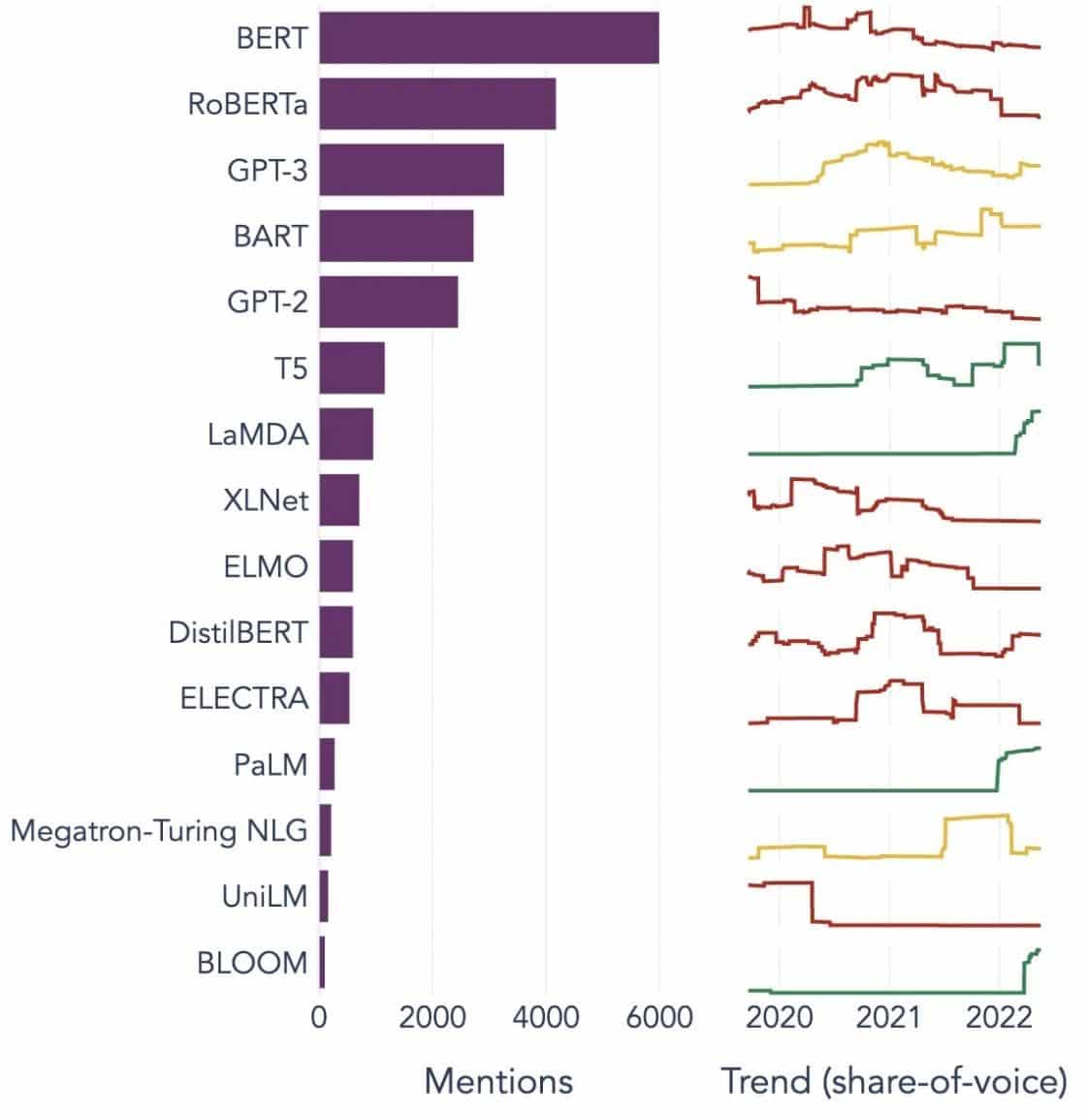
Bildquelle: Auf dem Weg zur Datenwissenschaft
Wie werden LLM-Modelle trainiert?
Das Training großer Sprachmodelle (LLMs) ist eine ziemliche Leistung, die mehrere entscheidende Schritte erfordert. Hier ist eine vereinfachte Schritt-für-Schritt-Übersicht des Prozesses:
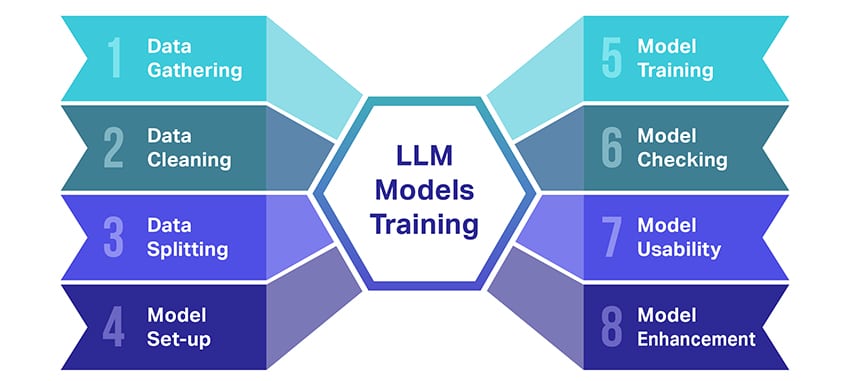
- Textdaten sammeln: Das Training eines LLM beginnt mit der Erfassung einer großen Menge an Textdaten. Diese Daten können aus Büchern, Websites, Artikeln oder Social-Media-Plattformen stammen. Ziel ist es, die reiche Vielfalt der menschlichen Sprache einzufangen.
- Bereinigen der Daten: Die Rohtextdaten werden dann in einem Prozess namens Vorverarbeitung bereinigt. Dazu gehören Aufgaben wie das Entfernen unerwünschter Zeichen, das Zerlegen des Textes in kleinere Teile, sogenannte Token, und das Überführen des Ganzen in ein Format, mit dem das Modell arbeiten kann.
- Aufteilen der Daten: Als nächstes werden die sauberen Daten in zwei Sätze aufgeteilt. Ein Satz, die Trainingsdaten, wird zum Trainieren des Modells verwendet. Der andere Satz, die Validierungsdaten, wird später zum Testen der Leistung des Modells verwendet.
- Einrichten des Modells: Anschließend wird die Struktur des LLM, die sogenannte Architektur, definiert. Dazu gehört die Auswahl des Typs des neuronalen Netzwerks und die Festlegung verschiedener Parameter, beispielsweise der Anzahl der Schichten und versteckten Einheiten innerhalb des Netzwerks.
- Trainieren des Modells: Nun beginnt das eigentliche Training. Das LLM-Modell lernt, indem es sich die Trainingsdaten ansieht, auf der Grundlage dessen, was es bisher gelernt hat, Vorhersagen trifft und dann seine internen Parameter anpasst, um den Unterschied zwischen seinen Vorhersagen und den tatsächlichen Daten zu verringern.
- Überprüfung des Modells: Das Lernen des LLM-Modells wird anhand der Validierungsdaten überprüft. Auf diese Weise können Sie sehen, wie gut das Modell funktioniert, und die Einstellungen des Modells optimieren, um eine bessere Leistung zu erzielen.
- Verwendung des Modells: Nach dem Training und der Evaluierung ist das LLM-Modell einsatzbereit. Es kann jetzt in Anwendungen oder Systeme integriert werden, wo es Text basierend auf neuen Eingaben generiert.
- Verbesserung des Modells: Schließlich gibt es immer Raum für Verbesserungen. Das LLM-Modell kann im Laufe der Zeit weiter verfeinert werden, indem aktualisierte Daten verwendet oder Einstellungen basierend auf Feedback und realer Nutzung angepasst werden.
Bedenken Sie, dass dieser Prozess erhebliche Rechenressourcen wie leistungsstarke Verarbeitungseinheiten und großen Speicher sowie Spezialkenntnisse im maschinellen Lernen erfordert. Aus diesem Grund wird dies in der Regel von engagierten Forschungsorganisationen oder Unternehmen durchgeführt, die über die erforderliche Infrastruktur und das erforderliche Fachwissen verfügen.
Verlässt sich das LLM auf überwachtes oder unüberwachtes Lernen?
Große Sprachmodelle werden normalerweise mit einer Methode trainiert, die als überwachtes Lernen bezeichnet wird. Vereinfacht ausgedrückt bedeutet dies, dass sie anhand von Beispielen lernen, die ihnen die richtigen Antworten zeigen.
 Stellen Sie sich vor, Sie bringen einem Kind Wörter bei, indem Sie ihm Bilder zeigen. Sie zeigen ihnen ein Bild einer Katze und sagen „Katze“, und sie lernen, dieses Bild mit dem Wort zu assoziieren. So funktioniert überwachtes Lernen. Das Modell erhält viel Text (die „Bilder“) und die entsprechenden Ausgaben (die „Wörter“) und lernt, diese zuzuordnen.
Stellen Sie sich vor, Sie bringen einem Kind Wörter bei, indem Sie ihm Bilder zeigen. Sie zeigen ihnen ein Bild einer Katze und sagen „Katze“, und sie lernen, dieses Bild mit dem Wort zu assoziieren. So funktioniert überwachtes Lernen. Das Modell erhält viel Text (die „Bilder“) und die entsprechenden Ausgaben (die „Wörter“) und lernt, diese zuzuordnen.
Wenn Sie also ein LLM mit einem Satz füttern, versucht es, das nächste Wort oder die nächste Phrase basierend auf dem, was es aus den Beispielen gelernt hat, vorherzusagen. Auf diese Weise lernt es, Texte zu generieren, die Sinn ergeben und zum Kontext passen.
Allerdings nutzen LLMs manchmal auch ein wenig unbeaufsichtigtes Lernen. Das ist so, als würde man das Kind einen Raum voller verschiedener Spielsachen erkunden und selbst etwas über sie lernen. Das Modell betrachtet unbeschriftete Daten, Lernmuster und Strukturen, ohne dass ihm die „richtigen“ Antworten gesagt werden.
Beim überwachten Lernen werden Daten verwendet, die mit Eingaben und Ausgaben gekennzeichnet sind, im Gegensatz zum unüberwachten Lernen, bei dem keine gekennzeichneten Ausgabedaten verwendet werden.
Kurz gesagt: LLMs werden hauptsächlich durch überwachtes Lernen trainiert, sie können jedoch auch unüberwachtes Lernen nutzen, um ihre Fähigkeiten zu verbessern, beispielsweise für explorative Analysen und Dimensionsreduktion.
Welches Datenvolumen (in GB) ist zum Trainieren eines großen Sprachmodells erforderlich?
Die Welt der Möglichkeiten für Sprachdatenerkennung und Sprachanwendungen ist immens und sie werden in mehreren Branchen für eine Vielzahl von Anwendungen eingesetzt.
Das Training eines großen Sprachmodells ist kein einheitlicher Prozess, insbesondere wenn es um die benötigten Daten geht. Es hängt von einer Reihe von Dingen ab:
- Der Modellentwurf.
- Welche Aufgabe muss es erfüllen?
- Die Art der Daten, die Sie verwenden.
- Wie gut soll es funktionieren?
Allerdings erfordert das Training von LLMs normalerweise eine riesige Menge an Textdaten. Aber von wie massiv reden wir? Denken Sie weit über Gigabyte (GB) hinaus. In der Regel handelt es sich um Terabytes (TB) oder sogar Petabytes (PB) an Daten.
Betrachten Sie GPT-3, eines der größten LLMs überhaupt. Darauf wird trainiert 570 GB Textdaten. Kleinere LLMs benötigen möglicherweise weniger – vielleicht 10–20 GB oder sogar 1 GB Gigabyte –, aber es ist immer noch viel.

Aber es kommt nicht nur auf die Größe der Daten an. Qualität ist auch wichtig. Die Daten müssen sauber und abwechslungsreich sein, damit das Modell effektiv lernen kann. Und Sie dürfen andere wichtige Puzzleteile nicht vergessen, wie die benötigte Rechenleistung, die Algorithmen, die Sie für das Training verwenden, und die Hardware-Ausstattung, die Sie haben. All diese Faktoren spielen bei der Ausbildung eines LLM eine große Rolle.
Der Aufstieg großer Sprachmodelle: Warum sie wichtig sind
LLMs sind nicht mehr nur ein Konzept oder ein Experiment. Sie spielen in unserer digitalen Landschaft zunehmend eine entscheidende Rolle. Aber warum passiert das? Was macht diese LLMs so wichtig? Lassen Sie uns auf einige Schlüsselfaktoren eingehen.
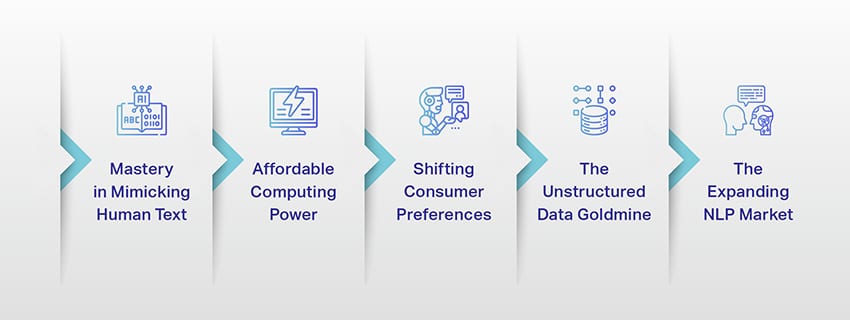
Beherrschung der Nachahmung menschlichen Textes
LLMs haben die Art und Weise, wie wir sprachbasierte Aufgaben bearbeiten, verändert. Diese Modelle basieren auf robusten Algorithmen für maschinelles Lernen und sind mit der Fähigkeit ausgestattet, die Nuancen der menschlichen Sprache zu verstehen, einschließlich Kontext, Emotionen und in gewissem Maße sogar Sarkasmus. Diese Fähigkeit, die menschliche Sprache nachzuahmen, ist keine bloße Neuheit, sie hat erhebliche Auswirkungen.
Die fortschrittlichen Textgenerierungsfähigkeiten von LLMs können alles von der Inhaltserstellung bis zur Interaktion mit dem Kundenservice verbessern.
Stellen Sie sich vor, Sie könnten einem digitalen Assistenten eine komplexe Frage stellen und eine Antwort erhalten, die nicht nur Sinn ergibt, sondern auch schlüssig und relevant ist und in einem verständlichen Ton vermittelt wird. Das ist es, was LLMs ermöglichen. Sie fördern eine intuitivere und ansprechendere Mensch-Maschine-Interaktion, bereichern das Benutzererlebnis und demokratisieren den Zugang zu Informationen.
Erschwingliche Rechenleistung
Der Aufstieg der LLMs wäre ohne parallele Entwicklungen im Bereich der Informatik nicht möglich gewesen. Genauer gesagt hat die Demokratisierung der Rechenressourcen eine bedeutende Rolle bei der Entwicklung und Einführung von LLMs gespielt.
Cloudbasierte Plattformen bieten einen beispiellosen Zugang zu Hochleistungs-Computing-Ressourcen. Auf diese Weise können auch kleine Organisationen und unabhängige Forscher anspruchsvolle Modelle für maschinelles Lernen trainieren.
Darüber hinaus haben Verbesserungen bei Verarbeitungseinheiten (wie GPUs und TPUs) in Verbindung mit dem Aufkommen verteilter Datenverarbeitung das Trainieren von Modellen mit Milliarden von Parametern möglich gemacht. Diese verbesserte Zugänglichkeit von Rechenleistung ermöglicht das Wachstum und den Erfolg von LLMs und führt zu mehr Innovationen und Anwendungen in diesem Bereich.
Veränderte Verbraucherpräferenzen
Verbraucher wollen heute nicht nur Antworten; Sie wollen ansprechende und nachvollziehbare Interaktionen. Da immer mehr Menschen mit digitaler Technologie aufwachsen, ist es offensichtlich, dass der Bedarf an Technologie, die sich natürlicher und menschlicher anfühlt, zunimmt. LLMs bieten eine beispiellose Gelegenheit, diese Erwartungen zu erfüllen. Durch die Generierung menschenähnlicher Texte können diese Modelle ansprechende und dynamische digitale Erlebnisse schaffen, die die Zufriedenheit und Loyalität der Benutzer erhöhen können. Ob KI-Chatbots für den Kundenservice oder Sprachassistenten für Nachrichtenaktualisierungen: LLMs läuten eine Ära der KI ein, die uns besser versteht.
Die Goldgrube für unstrukturierte Daten
Unstrukturierte Daten wie E-Mails, Social-Media-Beiträge und Kundenrezensionen sind eine Fundgrube an Erkenntnissen. Es wird geschätzt, dass das vorbei ist 80% der Unternehmensdaten sind unstrukturiert und wachsen mit einer Rate von 55% pro Jahr. Diese Daten sind eine Goldgrube für Unternehmen, wenn sie richtig genutzt werden.
Hier kommen LLMs mit ihrer Fähigkeit ins Spiel, solche Daten in großem Maßstab zu verarbeiten und zu verstehen. Sie können Aufgaben wie Sentimentanalyse, Textklassifizierung, Informationsextraktion und mehr übernehmen und so wertvolle Erkenntnisse liefern.
Ganz gleich, ob es darum geht, Trends aus Social-Media-Beiträgen zu erkennen oder die Kundenstimmung anhand von Bewertungen zu messen: LLMs helfen Unternehmen dabei, sich in der großen Menge unstrukturierter Daten zurechtzufinden und datengesteuerte Entscheidungen zu treffen.
Der expandierende NLP-Markt
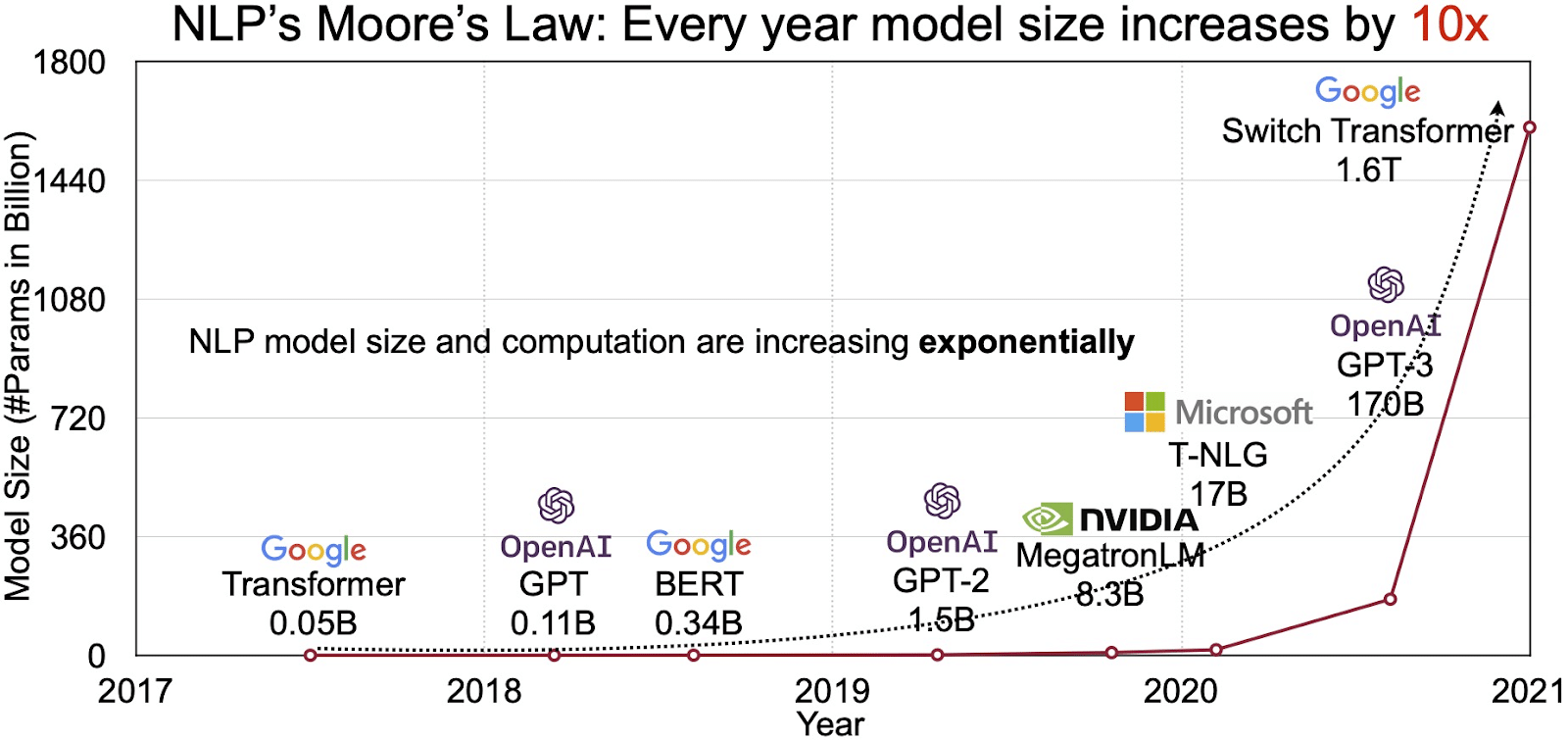
Das Potenzial von LLMs spiegelt sich im schnell wachsenden Markt für natürliche Sprachverarbeitung (NLP) wider. Analysten gehen davon aus, dass der NLP-Markt weiter wachsen wird 11 Milliarden US-Dollar im Jahr 2020 auf über 35 Milliarden US-Dollar im Jahr 2026. Aber nicht nur die Marktgröße wächst. Auch die Modelle selbst wachsen, sowohl in der physischen Größe als auch in der Anzahl der von ihnen verarbeiteten Parameter. Die Entwicklung von LLMs im Laufe der Jahre, wie in der Abbildung unten (Bildquelle: Link) zu sehen ist, unterstreicht ihre zunehmende Komplexität und Kapazität.
Beliebte Anwendungsfälle großer Sprachmodelle
Hier sind einige der wichtigsten und am weitesten verbreiteten Anwendungsfälle von LLM:
- Erzeugen von Text in natürlicher Sprache: Large Language Models (LLMs) kombinieren die Leistungsfähigkeit künstlicher Intelligenz und Computerlinguistik, um autonom Texte in natürlicher Sprache zu produzieren. Sie können auf unterschiedliche Benutzerbedürfnisse eingehen, z. B. das Verfassen von Artikeln, das Erstellen von Liedern oder die Teilnahme an Gesprächen mit Benutzern.
- Übersetzung durch Maschinen: LLMs können effektiv zum Übersetzen von Text zwischen beliebigen Sprachpaaren eingesetzt werden. Diese Modelle nutzen Deep-Learning-Algorithmen wie wiederkehrende neuronale Netze, um die sprachliche Struktur sowohl der Ausgangs- als auch der Zielsprache zu verstehen und so die Übersetzung des Ausgangstextes in die gewünschte Sprache zu erleichtern.
- Erstellen von Originalinhalten: LLMs haben Maschinen die Möglichkeit eröffnet, zusammenhängende und logische Inhalte zu generieren. Dieser Inhalt kann zum Erstellen von Blogbeiträgen, Artikeln und anderen Arten von Inhalten verwendet werden. Die Modelle nutzen ihre fundierte Deep-Learning-Erfahrung, um die Inhalte auf neuartige und benutzerfreundliche Weise zu formatieren und zu strukturieren.
- Stimmungen analysieren: Eine interessante Anwendung großer Sprachmodelle ist die Stimmungsanalyse. Dabei wird das Modell darauf trainiert, im annotierten Text vorhandene emotionale Zustände und Gefühle zu erkennen und zu kategorisieren. Die Software kann Emotionen wie Positivität, Negativität, Neutralität und andere komplexe Gefühle identifizieren. Dies kann wertvolle Erkenntnisse über Kundenfeedback und Ansichten zu verschiedenen Produkten und Dienstleistungen liefern.
- Text verstehen, zusammenfassen und klassifizieren: LLMs schaffen eine tragfähige Struktur für KI-Software zur Interpretation des Textes und seines Kontexts. Indem sie das Modell anweisen, riesige Datenmengen zu verstehen und zu untersuchen, ermöglichen LLMs KI-Modellen, Texte in verschiedenen Formen und Mustern zu verstehen, zusammenzufassen und sogar zu kategorisieren.
- Fragen beantworten: Große Sprachmodelle statten Frage-Antwort-Systeme (QA) mit der Fähigkeit aus, die Anfrage eines Benutzers in natürlicher Sprache genau wahrzunehmen und darauf zu reagieren. Beliebte Beispiele für diesen Anwendungsfall sind ChatGPT und BERT, die den Kontext einer Anfrage untersuchen und eine riesige Sammlung von Texten durchsuchen, um relevante Antworten auf Benutzerfragen zu liefern.

Part-of-Speech (POS)-Tagging
Wörter in Sätzen werden mit ihrer grammatikalischen Funktion markiert, beispielsweise Verben, Substantive, Adjektive usw. Dieser Prozess hilft dem Modell, die Grammatik und die Verknüpfungen zwischen Wörtern zu verstehen.

Anerkennung benannter Entitäten (NER)
Benannte Entitäten wie Organisationen, Standorte und Personen innerhalb eines Satzes werden markiert. Diese Übung unterstützt das Modell bei der Interpretation der semantischen Bedeutung von Wörtern und Phrasen und liefert präzisere Antworten.

Stimmungsanalyse
Den Textdaten werden Stimmungsbezeichnungen wie „positiv“, „neutral“ oder „negativ“ zugewiesen, die dem Modell helfen, den emotionalen Unterton von Sätzen zu erfassen. Es ist besonders nützlich bei der Beantwortung von Fragen, die Emotionen und Meinungen betreffen.
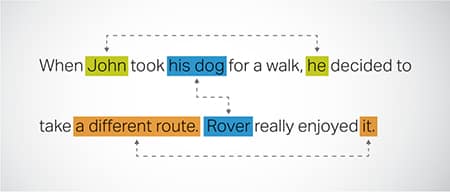
Koreferenzauflösung
Identifizieren und Beheben von Fällen, in denen in verschiedenen Teilen eines Textes auf dieselbe Entität verwiesen wird. Dieser Schritt hilft dem Modell, den Kontext des Satzes zu verstehen, und führt so zu kohärenten Antworten.
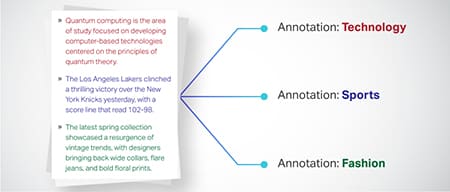
Textklassifizierung
Textdaten werden in vordefinierte Gruppen wie Produktbewertungen oder Nachrichtenartikel kategorisiert. Dies hilft dem Modell, das Genre oder Thema des Textes zu erkennen und relevantere Antworten zu generieren.
Shaips Opfergabe
Saip bietet eine breite Palette von Dienstleistungen an, die Unternehmen bei der Verwaltung, Analyse und optimalen Nutzung ihrer Daten unterstützen.
Daten-Web-Scraping
Ein wichtiger Service von Shaip ist das Data Scraping. Dabei handelt es sich um die Extraktion von Daten aus domänenspezifischen URLs. Durch den Einsatz automatisierter Tools und Techniken kann Shaip schnell und effizient große Datenmengen von verschiedenen Websites, Produkthandbüchern, technischen Dokumentationen, Online-Foren, Online-Bewertungen, Kundendienstdaten, Branchenregulierungsdokumenten usw. entfernen. Dieser Prozess kann für Unternehmen von unschätzbarem Wert sein, wenn Sammeln relevanter und spezifischer Daten aus einer Vielzahl von Quellen.

Maschinelle Übersetzung
Entwickeln Sie Modelle mithilfe umfangreicher mehrsprachiger Datensätze gepaart mit entsprechenden Transkriptionen für die Übersetzung von Texten in verschiedene Sprachen. Dieser Prozess trägt zum Abbau sprachlicher Hürden bei und fördert die Zugänglichkeit von Informationen.
Taxonomie-Extraktion und -Erstellung
Shaip kann bei der Extraktion und Erstellung von Taxonomien helfen. Dabei werden Daten in einem strukturierten Format klassifiziert und kategorisiert, das die Beziehungen zwischen verschiedenen Datenpunkten widerspiegelt. Dies kann besonders für Unternehmen nützlich sein, um ihre Daten zu organisieren und sie leichter zugänglich und einfacher zu analysieren. In einem E-Commerce-Unternehmen können Produktdaten beispielsweise nach Produkttyp, Marke, Preis usw. kategorisiert werden, um Kunden die Navigation im Produktkatalog zu erleichtern.
Datensammlung
Unsere Datenerfassungsdienste liefern wichtige reale oder synthetische Daten, die für das Training generativer KI-Algorithmen und die Verbesserung der Genauigkeit und Effektivität Ihrer Modelle erforderlich sind. Die Daten stammen aus unvoreingenommenen, ethisch vertretbaren und verantwortungsvollen Quellen unter Berücksichtigung von Datenschutz und Sicherheit.

Fragen und Antworten
Die Beantwortung von Fragen (QA) ist ein Teilbereich der Verarbeitung natürlicher Sprache, der sich auf die automatische Beantwortung von Fragen in menschlicher Sprache konzentriert. QA-Systeme werden anhand umfangreicher Texte und Codes geschult, sodass sie verschiedene Arten von Fragen bearbeiten können, darunter sachliche, definitorische und meinungsbasierte Fragen. Domänenkenntnisse sind für die Entwicklung von QA-Modellen, die auf bestimmte Bereiche wie Kundensupport, Gesundheitswesen oder Lieferkette zugeschnitten sind, von entscheidender Bedeutung. Generative QA-Ansätze ermöglichen es Modellen jedoch, Texte ohne Domänenkenntnisse zu generieren und sich ausschließlich auf den Kontext zu verlassen.
Unser Spezialistenteam kann umfassende Dokumente oder Handbücher sorgfältig studieren, um Frage-Antwort-Paare zu generieren und so die Entwicklung generativer KI für Unternehmen zu erleichtern. Dieser Ansatz kann Benutzeranfragen effektiv beantworten, indem er relevante Informationen aus einem umfangreichen Korpus extrahiert. Unsere zertifizierten Experten stellen die Erstellung hochwertiger Frage-und-Antwort-Paare sicher, die sich über verschiedene Themen und Bereiche erstrecken.

Textzusammenfassung
Unsere Spezialisten sind in der Lage, umfassende Gespräche oder lange Dialoge zu destillieren und aus umfangreichen Textdaten prägnante und aufschlussreiche Zusammenfassungen zu liefern.

Textgenerierung
Trainieren Sie Modelle mithilfe eines breiten Textdatensatzes in verschiedenen Stilrichtungen, z. B. Nachrichtenartikeln, Belletristik und Gedichten. Diese Modelle können dann verschiedene Arten von Inhalten generieren, darunter Nachrichtenbeiträge, Blogeinträge oder Social-Media-Beiträge, und bieten so eine kostengünstige und zeitsparende Lösung für die Inhaltserstellung.
Spracherkennung
Entwickeln Sie Modelle, die gesprochene Sprache für verschiedene Anwendungen verstehen können. Dazu gehören sprachaktivierte Assistenten, Diktiersoftware und Echtzeit-Übersetzungstools. Der Prozess umfasst die Verwendung eines umfassenden Datensatzes, der aus Audioaufzeichnungen gesprochener Sprache besteht, gepaart mit den entsprechenden Transkripten.

Produktempfehlungen
Entwickeln Sie Modelle anhand umfangreicher Datensätze zur Kaufhistorie von Kunden, einschließlich Etiketten, die darauf hinweisen, welche Produkte Kunden kaufen möchten. Ziel ist es, den Kunden präzise Vorschläge zu machen und so den Umsatz anzukurbeln und die Kundenzufriedenheit zu steigern.
Bilduntertitelung
Revolutionieren Sie Ihren Bildinterpretationsprozess mit unserem hochmodernen, KI-gesteuerten Bildunterschriftenservice. Wir verleihen Bildern Lebendigkeit, indem wir genaue und kontextbedeutende Beschreibungen erstellen. Dies ebnet den Weg für innovative Engagement- und Interaktionsmöglichkeiten mit Ihren visuellen Inhalten für Ihr Publikum.

Schulung von Text-to-Speech-Diensten
Wir stellen einen umfangreichen Datensatz aus Audioaufzeichnungen menschlicher Sprache bereit, der sich ideal für das Training von KI-Modellen eignet. Diese Modelle sind in der Lage, natürliche und ansprechende Stimmen für Ihre Anwendungen zu erzeugen und so Ihren Benutzern ein unverwechselbares und immersives Klangerlebnis zu bieten.



