
Einleitung
Dieser Leitfaden ist äußerst hilfreich für Käufer und Entscheidungsträger, die beginnen, sich mit den Grundlagen der Datenbeschaffung und Datenimplementierung sowohl für neuronale Netze als auch für andere Arten von KI- und ML-Vorgängen zu befassen.

Dieser Artikel widmet sich ganz der Aufklärung darüber, was der Prozess ist, warum er unvermeidlich und entscheidend ist
Faktoren, die Unternehmen bei der Herangehensweise an Datenannotationstools und mehr berücksichtigen sollten. Wenn Sie also ein Unternehmen besitzen, bereiten Sie sich darauf vor, aufgeklärt zu werden, denn dieser Leitfaden führt Sie durch alles, was Sie über die Datenannotation wissen müssen.
Fangen wir an.
Für diejenigen unter Ihnen, die den Artikel überfliegen, finden Sie hier einige schnelle Erkenntnisse, die Sie im Leitfaden finden:
- Verstehen, was Datenanmerkung ist
- Kennen Sie die verschiedenen Arten von Datenannotationsprozessen
- Kennen Sie die Vorteile der Implementierung des Datenannotationsprozesses
- Verschaffen Sie sich Klarheit darüber, ob Sie sich für eine interne Datenkennzeichnung entscheiden oder diese auslagern lassen sollten
- Einblicke auch in die Auswahl der richtigen Datenanmerkung
Was ist maschinelles Lernen?
 Wir haben darüber gesprochen, wie Datenannotation oder Datenkennzeichnung unterstützt maschinelles Lernen und besteht aus dem Markieren oder Identifizieren von Komponenten. Aber was Deep Learning und maschinelles Lernen selbst betrifft: Die grundlegende Prämisse des maschinellen Lernens ist, dass Computersysteme und -programme ihre Ergebnisse auf eine Weise verbessern können, die menschlichen kognitiven Prozessen ähnelt, ohne direkte menschliche Hilfe oder Intervention, um uns Erkenntnisse zu geben. Mit anderen Worten, sie werden zu selbstlernenden Maschinen, die wie ein Mensch mit mehr Übung ihre Arbeit besser machen. Diese „Praxis“ wird durch die Analyse und Interpretation von mehr (und besseren) Trainingsdaten gewonnen.
Wir haben darüber gesprochen, wie Datenannotation oder Datenkennzeichnung unterstützt maschinelles Lernen und besteht aus dem Markieren oder Identifizieren von Komponenten. Aber was Deep Learning und maschinelles Lernen selbst betrifft: Die grundlegende Prämisse des maschinellen Lernens ist, dass Computersysteme und -programme ihre Ergebnisse auf eine Weise verbessern können, die menschlichen kognitiven Prozessen ähnelt, ohne direkte menschliche Hilfe oder Intervention, um uns Erkenntnisse zu geben. Mit anderen Worten, sie werden zu selbstlernenden Maschinen, die wie ein Mensch mit mehr Übung ihre Arbeit besser machen. Diese „Praxis“ wird durch die Analyse und Interpretation von mehr (und besseren) Trainingsdaten gewonnen.
Was ist Datenanmerkung?
Datenannotation ist der Prozess des Zuordnens, Markierens oder Kennzeichnens von Daten, um maschinellen Lernalgorithmen dabei zu helfen, die von ihnen verarbeiteten Informationen zu verstehen und zu klassifizieren. Dieser Prozess ist für das Training von KI-Modellen unerlässlich, damit sie verschiedene Datentypen wie Bilder, Audiodateien, Videomaterial oder Text genau verstehen können.
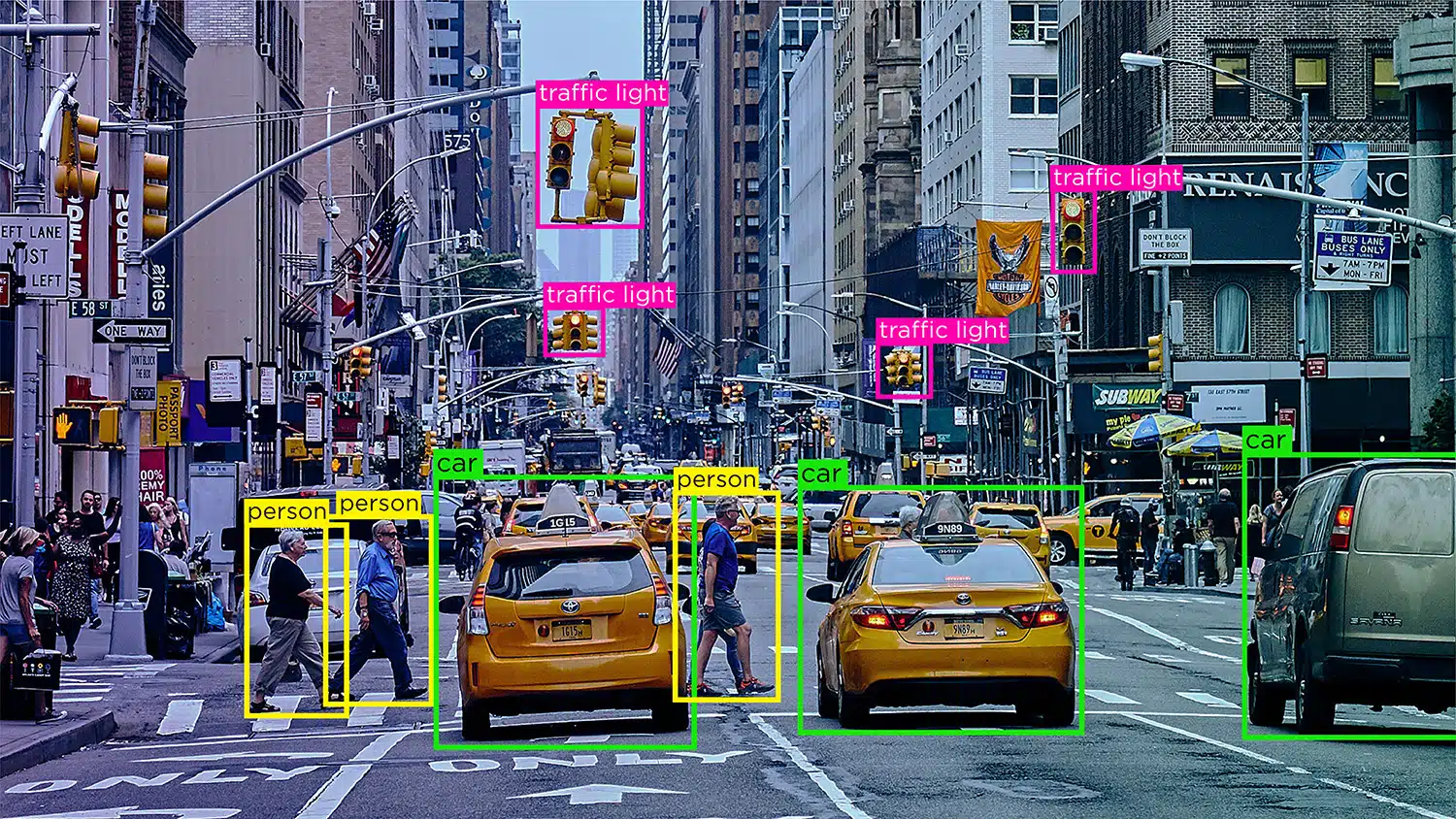
Stellen Sie sich ein selbstfahrendes Auto vor, das auf Daten aus Computer Vision, Verarbeitung natürlicher Sprache (NLP) und Sensoren angewiesen ist, um genaue Fahrentscheidungen zu treffen. Damit das KI-Modell des Autos zwischen Hindernissen wie anderen Fahrzeugen, Fußgängern, Tieren oder Straßensperren unterscheiden kann, müssen die empfangenen Daten beschriftet oder kommentiert werden.
Beim überwachten Lernen ist die Datenannotation besonders wichtig, denn je mehr beschriftete Daten in das Modell eingespeist werden, desto schneller lernt es, autonom zu funktionieren. Annotierte Daten ermöglichen den Einsatz von KI-Modellen in verschiedenen Anwendungen wie Chatbots, Spracherkennung und Automatisierung, was zu optimaler Leistung und zuverlässigen Ergebnissen führt.
Was ist ein Datenkennzeichnungs-/Anmerkungstool?
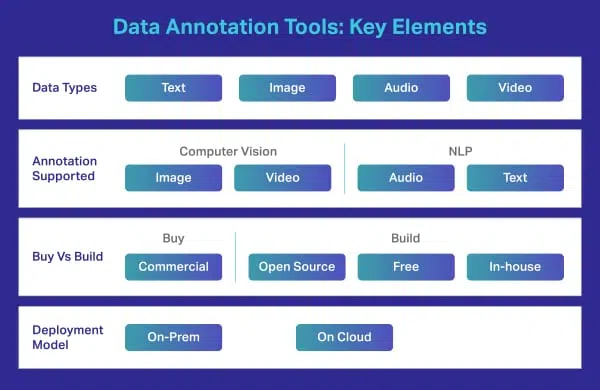 Einfach ausgedrückt ist es eine Plattform oder ein Portal, mit dem Spezialisten und Experten Datensätze aller Art kommentieren, markieren oder beschriften können. Es ist eine Brücke oder ein Medium zwischen Rohdaten und den Ergebnissen, die Ihre Module für maschinelles Lernen letztendlich liefern würden.
Einfach ausgedrückt ist es eine Plattform oder ein Portal, mit dem Spezialisten und Experten Datensätze aller Art kommentieren, markieren oder beschriften können. Es ist eine Brücke oder ein Medium zwischen Rohdaten und den Ergebnissen, die Ihre Module für maschinelles Lernen letztendlich liefern würden.
Ein Tool zur Datenkennzeichnung ist eine lokale oder cloudbasierte Lösung, die hochwertige Trainingsdaten für Modelle für maschinelles Lernen mit Anmerkungen versehen. Während sich viele Unternehmen für die Erstellung komplexer Anmerkungen auf einen externen Anbieter verlassen, haben einige Unternehmen immer noch ihre eigenen Tools, die entweder maßgeschneidert sind oder auf Freeware- oder Open-Source-Tools basieren, die auf dem Markt erhältlich sind. Solche Werkzeuge sind normalerweise dafür ausgelegt, bestimmte Datentypen zu handhaben, dh Bild, Video, Text, Audio usw. Die Werkzeuge bieten Funktionen oder Optionen wie Begrenzungsrahmen oder Polygone für Datenannotatoren zum Beschriften von Bildern. Sie können einfach die Option auswählen und ihre spezifischen Aufgaben ausführen.
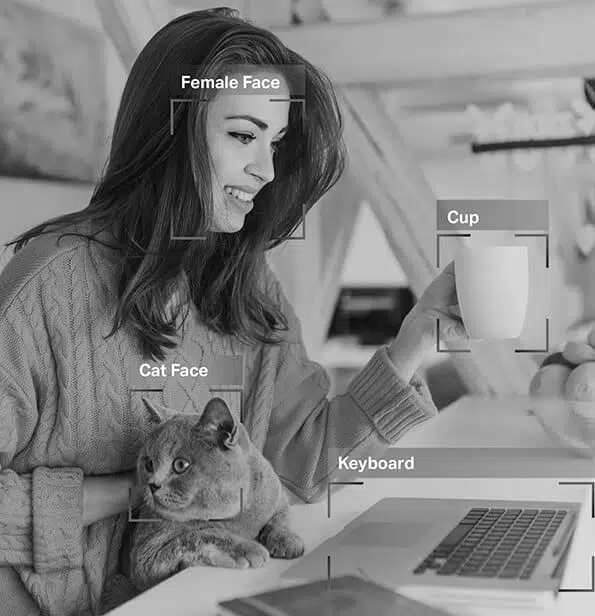
Bildanmerkung

Anhand der trainierten Datensätze können sie Ihre Augen sofort und präzise von Ihrer Nase und Ihre Augenbrauen von Ihren Wimpern unterscheiden. Aus diesem Grund passen die von Ihnen angewendeten Filter unabhängig von Ihrer Gesichtsform, Ihrer Kameranähe und vielem mehr perfekt.
Also, wie Sie jetzt wissen, Bildanmerkung ist in Modulen, die Gesichtserkennung, Computer Vision, Robotic Vision und mehr beinhalten, von entscheidender Bedeutung. Wenn KI-Experten solche Modelle trainieren, fügen sie ihren Bildern Bildunterschriften, Bezeichner und Schlüsselwörter als Attribute hinzu. Die Algorithmen identifizieren und verstehen dann diese Parameter und lernen autonom.
Bildklassifizierung – Bei der Bildklassifizierung werden Bildern anhand ihres Inhalts vordefinierte Kategorien oder Labels zugewiesen. Diese Art der Annotation wird verwendet, um KI-Modelle zu trainieren, Bilder automatisch zu erkennen und zu kategorisieren.
Objekterkennung/-detektion – Die Objekterkennung oder Objekterkennung ist der Prozess der Identifizierung und Kennzeichnung bestimmter Objekte in einem Bild. Diese Art der Annotation wird verwendet, um KI-Modelle zu trainieren, Objekte in realen Bildern oder Videos zu lokalisieren und zu erkennen.
Segmentierung – Bei der Bildsegmentierung wird ein Bild in mehrere Segmente oder Bereiche unterteilt, die jeweils einem bestimmten Objekt oder Interessenbereich entsprechen. Diese Art der Annotation wird verwendet, um KI-Modelle für die Analyse von Bildern auf Pixelebene zu trainieren, was eine genauere Objekterkennung und ein besseres Szenenverständnis ermöglicht.
Audiokommentar
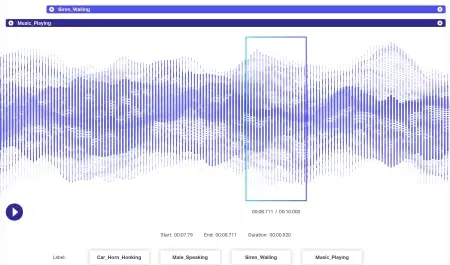
Audiodaten haben noch mehr Dynamik als Bilddaten. Mehrere Faktoren sind mit einer Audiodatei verbunden, einschließlich, aber nicht beschränkt auf – Sprache, Sprecherdemografie, Dialekte, Stimmung, Absicht, Emotion, Verhalten. Damit Algorithmen effizient in der Verarbeitung sind, sollten alle diese Parameter durch Techniken wie Zeitstempel, Audio-Labeling und mehr identifiziert und markiert werden. Neben rein verbalen Hinweisen könnten auch nonverbale Vorkommnisse wie Stille, Atemzüge und sogar Hintergrundgeräusche kommentiert werden, damit Systeme umfassend verstanden werden.
Videoanmerkung

Während ein Bild stillsteht, ist ein Video eine Zusammenstellung von Bildern, die den Effekt von bewegten Objekten erzeugen. Nun wird jedes Bild in dieser Zusammenstellung als Rahmen bezeichnet. Was die Videoanmerkung betrifft, beinhaltet der Prozess das Hinzufügen von Eigenpunkten, Polygonen oder Begrenzungsboxen, um unterschiedliche Objekte im Feld in jedem Frame zu kommentieren.
Wenn diese Rahmen zusammengefügt werden, können Bewegung, Verhalten, Muster und mehr von den KI-Modellen in Aktion gelernt werden. Es geht nur durch Video-Annotation dass Konzepte wie Lokalisierung, Bewegungsunschärfe und Objektverfolgung in Systemen implementiert werden könnten.
Textanmerkung

Heutzutage sind die meisten Unternehmen auf textbasierte Daten angewiesen, um einzigartige Einblicke und Informationen zu erhalten. Text kann jetzt alles sein, von Kundenfeedback zu einer App bis hin zu einer Erwähnung in sozialen Medien. Und im Gegensatz zu Bildern und Videos, die meist geradlinige Absichten vermitteln, hat Text viel Semantik.
Als Menschen sind wir darauf eingestellt, den Kontext eines Satzes, die Bedeutung jedes Wortes, Satzes oder Satzes zu verstehen, ihn auf eine bestimmte Situation oder ein Gespräch zu beziehen und dann die ganzheitliche Bedeutung einer Aussage zu erkennen. Maschinen hingegen können dies nicht auf genauen Ebenen tun. Begriffe wie Sarkasmus, Humor und andere abstrakte Elemente sind ihnen unbekannt und deshalb wird die Beschriftung von Textdaten schwieriger. Aus diesem Grund hat die Textannotation einige verfeinerte Stufen wie die folgenden:
Semantische Annotation – Gegenstände, Produkte und Dienstleistungen werden durch geeignete Schlüsselwort-Tagging- und Identifikationsparameter relevanter gemacht. Chatbots sind auch dazu gemacht, menschliche Gespräche auf diese Weise nachzuahmen.
Absichtsanmerkung – die Absicht eines Benutzers und die von ihm verwendete Sprache werden markiert, damit Maschinen sie verstehen. Damit können Models eine Anfrage von einem Befehl oder eine Empfehlung von einer Buchung usw. unterscheiden.
Sentiment-Anmerkung – Sentiment Annotation beinhaltet die Kennzeichnung von Textdaten mit der Stimmung, die sie vermitteln, wie z. B. positiv, negativ oder neutral. Diese Art der Annotation wird häufig in der Stimmungsanalyse verwendet, bei der KI-Modelle darauf trainiert werden, die im Text ausgedrückten Emotionen zu verstehen und zu bewerten.

Entitätsanmerkung – wo unstrukturierte Sätze mit Tags versehen werden, um sie aussagekräftiger zu machen und in ein maschinenlesbares Format zu bringen. Um dies zu erreichen, spielen zwei Aspekte eine Rolle – Erkennung benannter Entitäten und Entitätsverknüpfung. Bei der Erkennung benannter Entitäten werden Namen von Orten, Personen, Ereignissen, Organisationen und mehr markiert und identifiziert, und Entitätsverknüpfung ist, wenn diese Tags mit Sätzen, Phrasen, Fakten oder Meinungen verknüpft werden, die ihnen folgen. Zusammengenommen stellen diese beiden Prozesse die Beziehung zwischen den zugehörigen Texten und der sie umgebenden Aussage her.
Textkategorisierung – Sätze oder Absätze können anhand von übergreifenden Themen, Trends, Themen, Meinungen, Kategorien (Sport, Unterhaltung und ähnliches) und anderen Parametern verschlagwortet und klassifiziert werden.
Wichtige Schritte bei der Datenkennzeichnung und Datenanmerkung
Der Datenannotationsprozess umfasst eine Reihe klar definierter Schritte, um eine qualitativ hochwertige und genaue Datenkennzeichnung für maschinelle Lernanwendungen sicherzustellen. Diese Schritte decken jeden Aspekt des Prozesses ab, von der Datenerfassung bis zum Export der annotierten Daten zur weiteren Verwendung.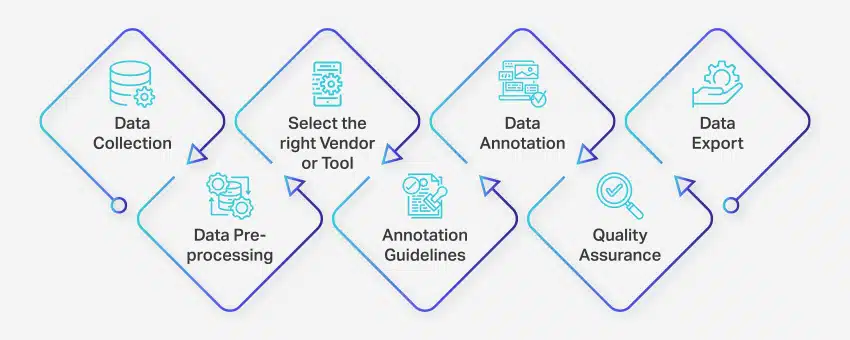
So findet die Datenannotation statt:
- Datensammlung: Der erste Schritt im Datenannotationsprozess besteht darin, alle relevanten Daten wie Bilder, Videos, Audioaufzeichnungen oder Textdaten an einem zentralen Ort zu sammeln.
- Datenvorverarbeitung: Standardisieren und verbessern Sie die gesammelten Daten, indem Sie Bilder geraderichten, Text formatieren oder Videoinhalte transkribieren. Die Vorverarbeitung stellt sicher, dass die Daten für die Annotation bereit sind.
- Wählen Sie den richtigen Anbieter oder das richtige Tool aus: Wählen Sie basierend auf den Anforderungen Ihres Projekts ein geeignetes Datenannotationstool oder einen geeigneten Anbieter aus. Zu den Optionen gehören Plattformen wie Nanonets für die Datenanmerkung, V7 für die Bildanmerkung, Appen für die Videoanmerkung und Nanonets für die Dokumentanmerkung.
- Anmerkungsrichtlinien: Legen Sie klare Richtlinien für Kommentatoren oder Kommentierungswerkzeuge fest, um Konsistenz und Genauigkeit während des gesamten Prozesses zu gewährleisten.
- Anmerkung: Beschriften und taggen Sie die Daten mit menschlichen Annotatoren oder Datenannotationssoftware gemäß den festgelegten Richtlinien.
- Qualitätssicherung (QS): Überprüfen Sie die annotierten Daten, um Genauigkeit und Konsistenz sicherzustellen. Verwenden Sie ggf. mehrere blinde Anmerkungen, um die Qualität der Ergebnisse zu überprüfen.
- Datenexport: Exportieren Sie nach Abschluss der Datenanmerkung die Daten im erforderlichen Format. Plattformen wie Nanonets ermöglichen einen nahtlosen Datenexport in verschiedene Business-Softwareanwendungen.
Der gesamte Datenanmerkungsprozess kann je nach Größe, Komplexität und verfügbaren Ressourcen des Projekts einige Tage bis mehrere Wochen dauern.
Funktionen für Datenanmerkungs- und Datenkennzeichnungstools
Datenannotationstools sind entscheidende Faktoren, die Ihr KI-Projekt ausmachen oder zerstören können. Wenn es um präzise Outputs und Ergebnisse geht, spielt die Qualität der Datensätze allein keine Rolle. Tatsächlich beeinflussen die Datenannotationstools, mit denen Sie Ihre KI-Module trainieren, Ihre Ausgaben immens.
Aus diesem Grund ist es wichtig, das funktionalste und geeignetste Datenkennzeichnungstool auszuwählen und zu verwenden, das Ihren Geschäfts- oder Projektanforderungen entspricht. Aber was ist ein Data-Annotation-Tool überhaupt? Welchem Zweck dient es? Gibt es Typen? Nun, lass es uns herausfinden.
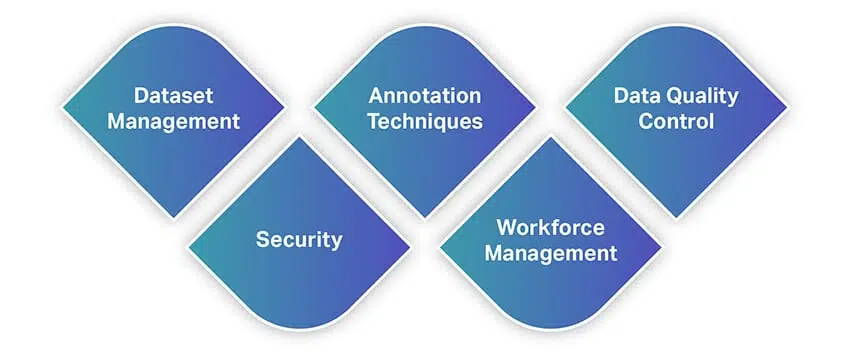
Ähnlich wie andere Tools bieten Datenannotationstools eine breite Palette von Funktionen und Fähigkeiten. Um Ihnen einen schnellen Überblick über die Funktionen zu geben, finden Sie hier eine Liste mit einigen der grundlegendsten Funktionen, auf die Sie bei der Auswahl eines Datenanmerkungswerkzeugs achten sollten.
Datensatzverwaltung
Das von Ihnen zu verwendende Datenannotationstool muss die von Ihnen vorliegenden Datensätze unterstützen und Sie zum Beschriften in die Software importieren können. Die Verwaltung Ihrer Datasets ist also das Hauptangebot der Feature-Tools. Moderne Lösungen bieten Funktionen, mit denen Sie große Datenmengen nahtlos importieren und gleichzeitig Ihre Datensätze durch Aktionen wie Sortieren, Filtern, Klonen, Zusammenführen und mehr organisieren können.
Sobald die Eingabe Ihrer Datensätze abgeschlossen ist, exportieren Sie sie als verwendbare Dateien. Das von Ihnen verwendete Tool sollte es Ihnen ermöglichen, Ihre Datasets in dem von Ihnen angegebenen Format zu speichern, damit Sie sie in Ihre ML-Modelle einspeisen können.
Anmerkungstechniken
Dafür wurde ein Datenannotationstool entwickelt oder entwickelt. Ein solides Werkzeug sollte Ihnen eine Reihe von Anmerkungstechniken für Datensätze aller Art bieten. Es sei denn, Sie entwickeln eine benutzerdefinierte Lösung für Ihre Anforderungen. Ihr Tool sollte es Ihnen ermöglichen, Videos oder Bilder aus Computer Vision, Audio oder Text aus NLPs und Transkriptionen und mehr zu kommentieren. Um dies weiter zu verfeinern, sollten Optionen zur Verwendung von Bounding Boxes, semantischer Segmentierung, Quadern, Interpolation, Sentimentanalyse, Wortarten, Koreferenzlösung und mehr vorhanden sein.
Für Uneingeweihte gibt es auch KI-gestützte Datenannotationstools. Diese kommen mit KI-Modulen, die selbstständig aus den Arbeitsmustern eines Annotators lernen und Bilder oder Text automatisch kommentieren. Eine solche
Module können verwendet werden, um Annotatoren unglaublich zu unterstützen, Annotationen zu optimieren und sogar Qualitätsprüfungen durchzuführen.
Datenqualitätskontrolle
Apropos Qualitätsprüfungen: Mehrere Datenannotationstools werden mit eingebetteten Qualitätsprüfungsmodulen eingeführt. Dadurch können Annotatoren besser mit ihren Teammitgliedern zusammenarbeiten und Arbeitsabläufe optimieren. Mit dieser Funktion können Kommentatoren Kommentare oder Feedback in Echtzeit markieren und verfolgen, Identitäten hinter Personen verfolgen, die Änderungen an Dateien vornehmen, frühere Versionen wiederherstellen, sich für die Kennzeichnung von Konsens entscheiden und vieles mehr.
Sicherheit
Da Sie mit Daten arbeiten, sollte Sicherheit höchste Priorität haben. Möglicherweise arbeiten Sie an vertraulichen Daten, die personenbezogene Daten oder geistiges Eigentum beinhalten. Daher muss Ihr Tool absolut sicher sein, wo die Daten gespeichert und wie sie weitergegeben werden. Es muss Tools bereitstellen, die den Zugriff auf Teammitglieder beschränken, nicht autorisierte Downloads verhindern und mehr.
Darüber hinaus müssen Sicherheitsstandards und -protokolle erfüllt und eingehalten werden.
Personalmanagement
Ein Data-Annotation-Tool ist auch eine Art Projektmanagement-Plattform, auf der Teammitgliedern Aufgaben zugewiesen werden, kollaboratives Arbeiten stattfinden kann, Reviews möglich sind und vieles mehr. Aus diesem Grund sollte sich Ihr Werkzeug für eine optimierte Produktivität in Ihren Workflow und Prozess einfügen.
Außerdem muss das Tool auch eine minimale Lernkurve aufweisen, da der Prozess der Datenannotation selbst zeitaufwändig ist. Es hat keinen Zweck, zu viel Zeit damit zu verbringen, das Tool einfach zu erlernen. Es sollte also intuitiv und nahtlos sein, damit jeder schnell loslegen kann.
Was sind die Vorteile der Datenannotation?
Die Datenannotation ist entscheidend für die Optimierung von maschinellen Lernsystemen und die Bereitstellung verbesserter Benutzererfahrungen. Hier sind einige der wichtigsten Vorteile der Datenannotation:
- Verbesserte Trainingseffizienz: Die Datenkennzeichnung hilft dabei, maschinelle Lernmodelle besser zu trainieren, die Gesamteffizienz zu steigern und genauere Ergebnisse zu erzielen.
- Erhöhte Präzision: Präzise annotierte Daten stellen sicher, dass sich Algorithmen effektiv anpassen und lernen können, was zu einer höheren Präzision bei zukünftigen Aufgaben führt.
- Reduzierte menschliche Intervention: Fortschrittliche Tools zur Datenanmerkung verringern den Bedarf an manuellen Eingriffen erheblich, rationalisieren Prozesse und reduzieren die damit verbundenen Kosten.
Somit trägt die Datenannotation zu effizienteren und präziseren maschinellen Lernsystemen bei und minimiert gleichzeitig die Kosten und den manuellen Aufwand, die traditionell zum Trainieren von KI-Modellen erforderlich sind.
So erstellen Sie ein Data-Annotation-Tool oder erstellen es nicht
Ein kritisches und übergreifendes Problem, das während eines Datenannotations- oder Datenkennzeichnungsprojekts auftreten kann, ist die Entscheidung, Funktionen für diese Prozesse entweder zu erstellen oder zu kaufen. Dies kann in verschiedenen Projektphasen mehrmals vorkommen oder sich auf unterschiedliche Programmabschnitte beziehen. Bei der Entscheidung, ob Sie ein System intern erstellen oder sich auf Anbieter verlassen möchten, müssen Sie immer einen Kompromiss eingehen.

Wie Sie jetzt wahrscheinlich feststellen können, ist die Datenannotation ein komplexer Prozess. Gleichzeitig ist es auch ein subjektiver Prozess. Das heißt, es gibt keine einheitliche Antwort auf die Frage, ob Sie ein Data-Annotation-Tool kaufen oder bauen sollten. Viele Faktoren müssen berücksichtigt werden und Sie müssen sich einige Fragen stellen, um Ihre Anforderungen zu verstehen und zu erkennen, ob Sie tatsächlich einen kaufen oder bauen müssen.
Um dies zu vereinfachen, sind hier einige der Faktoren, die Sie berücksichtigen sollten.
Dein Ziel
Das erste Element, das Sie definieren müssen, ist das Ziel mit Ihren Konzepten für künstliche Intelligenz und maschinelles Lernen.
- Warum implementieren Sie sie in Ihrem Unternehmen?
- Lösen sie ein reales Problem, mit dem Ihre Kunden konfrontiert sind?
- Führen sie einen Front-End- oder Back-End-Prozess durch?
- Werden Sie KI nutzen, um neue Funktionen einzuführen oder Ihre bestehende Website, App oder ein Modul zu optimieren?
- Was macht Ihr Wettbewerber in Ihrem Segment?
- Haben Sie genügend Anwendungsfälle, die eine KI-Intervention benötigen?
Antworten darauf bündeln Ihre Gedanken – die derzeit vielleicht überall präsent sind – an einem Ort und verschaffen Ihnen mehr Klarheit.
KI-Datenerfassung / Lizenzierung
KI-Modelle benötigen nur ein Element zum Funktionieren – Daten. Sie müssen herausfinden, woher Sie riesige Mengen an Ground-Truth-Daten generieren können. Wenn Ihr Unternehmen große Datenmengen generiert, die für wichtige Erkenntnisse über Geschäft, Betrieb, Wettbewerbsforschung, Marktvolatilitätsanalyse, Kundenverhaltensstudie und mehr verarbeitet werden müssen, benötigen Sie ein Datenanmerkungstool. Sie sollten jedoch auch die Datenmenge berücksichtigen, die Sie generieren. Wie bereits erwähnt, ist ein KI-Modell nur so effektiv wie die Qualität und Quantität der zugeführten Daten. Ihre Entscheidungen sollten also ausnahmslos von diesem Faktor abhängen.
Wenn Sie nicht über die richtigen Daten zum Trainieren Ihrer ML-Modelle verfügen, können sich Anbieter als sehr praktisch erweisen, die Sie bei der Datenlizenzierung des richtigen Datensatzes zum Trainieren von ML-Modellen unterstützen. In einigen Fällen umfasst ein Teil des Werts, den der Anbieter einbringt, sowohl technisches Können als auch Zugang zu Ressourcen, die den Projekterfolg fördern.
Preis
Eine weitere grundlegende Bedingung, die wahrscheinlich jeden einzelnen Faktor beeinflusst, den wir derzeit diskutieren. Die Lösung für die Frage, ob Sie eine Datenannotation erstellen oder kaufen sollten, wird einfach, wenn Sie verstehen, ob Sie über genügend Budget verfügen.
Compliance-Komplexitäten
 Anbieter können sehr hilfreich sein, wenn es um Datenschutz und den richtigen Umgang mit sensiblen Daten geht. Einer dieser Anwendungsfälle betrifft ein Krankenhaus oder ein gesundheitsbezogenes Unternehmen, das die Leistungsfähigkeit des maschinellen Lernens nutzen möchte, ohne die Einhaltung von HIPAA und anderen Datenschutzbestimmungen zu gefährden. Auch außerhalb des medizinischen Bereichs verschärfen Gesetze wie die europäische DSGVO die Kontrolle von Datensätzen und erfordern mehr Wachsamkeit seitens der Unternehmensakteure.
Anbieter können sehr hilfreich sein, wenn es um Datenschutz und den richtigen Umgang mit sensiblen Daten geht. Einer dieser Anwendungsfälle betrifft ein Krankenhaus oder ein gesundheitsbezogenes Unternehmen, das die Leistungsfähigkeit des maschinellen Lernens nutzen möchte, ohne die Einhaltung von HIPAA und anderen Datenschutzbestimmungen zu gefährden. Auch außerhalb des medizinischen Bereichs verschärfen Gesetze wie die europäische DSGVO die Kontrolle von Datensätzen und erfordern mehr Wachsamkeit seitens der Unternehmensakteure.
Arbeitskräfte
Die Datenannotation erfordert qualifiziertes Personal, um unabhängig von der Größe, dem Umfang und der Domäne Ihres Unternehmens zu arbeiten. Auch wenn Sie jeden Tag ein Minimum an Daten generieren, benötigen Sie Datenexperten, die an Ihren Daten für die Kennzeichnung arbeiten. Jetzt müssen Sie also erkennen, ob Sie über die erforderliche Arbeitskraft verfügen. Wenn ja, sind sie mit den erforderlichen Werkzeugen und Techniken vertraut oder müssen weiterqualifiziert werden? Wenn sie weiterqualifiziert werden müssen, haben Sie das Budget, um sie überhaupt auszubilden?
Darüber hinaus nehmen die besten Datenannotations- und Datenkennzeichnungsprogramme eine Reihe von Fach- oder Domänenexperten und segmentieren sie nach demografischen Merkmalen wie Alter, Geschlecht und Fachgebiet – oder oft in Bezug auf die lokalisierten Sprachen, mit denen sie arbeiten werden. Auch hier sprechen wir bei Shaip darüber, die richtigen Leute auf die richtigen Plätze zu bringen und so die richtigen Human-in-the-Loop-Prozesse voranzutreiben, die Ihre programmatischen Bemühungen zum Erfolg führen.
Klein- und Großprojektbetrieb und Kostenschwellen
In vielen Fällen kann der Herstellersupport eher für ein kleineres Projekt oder für kleinere Projektphasen eine Option sein. Wenn die Kosten kontrollierbar sind, kann das Unternehmen vom Outsourcing profitieren, um Datenannotations- oder Datenkennzeichnungsprojekte effizienter zu gestalten.
Unternehmen können sich auch wichtige Schwellenwerte ansehen – bei denen viele Anbieter die Kosten an die verbrauchte Datenmenge oder andere Ressourcen-Benchmarks binden. Angenommen, ein Unternehmen hat sich bei einem Anbieter angemeldet, um die mühsame Dateneingabe durchzuführen, die zum Einrichten von Testsätzen erforderlich ist.
In der Vereinbarung kann es einen versteckten Schwellenwert geben, bei dem der Geschäftspartner beispielsweise einen weiteren AWS-Datenspeicherblock oder eine andere Servicekomponente von Amazon Web Services oder einem anderen Drittanbieter entfernen muss. Das geben sie in Form von höheren Kosten an den Kunden weiter, und das Preisschild ist für den Kunden unerreichbar.
In diesen Fällen trägt die Messung der Dienste, die Sie von den Anbietern erhalten, dazu bei, das Projekt erschwinglich zu halten. Durch den richtigen Umfang wird sichergestellt, dass die Projektkosten das für das jeweilige Unternehmen zumutbare oder machbare Maß nicht überschreiten.
Open Source- und Freeware-Alternativen
 Einige Alternativen zur vollständigen Herstellerunterstützung beinhalten die Verwendung von Open-Source-Software oder sogar Freeware, um Datenanmerkungs- oder Kennzeichnungsprojekte durchzuführen. Hier gibt es eine Art Mittelweg, in dem Unternehmen nicht alles von Grund auf neu erstellen, sondern auch vermeiden, sich zu sehr auf kommerzielle Anbieter zu verlassen.
Einige Alternativen zur vollständigen Herstellerunterstützung beinhalten die Verwendung von Open-Source-Software oder sogar Freeware, um Datenanmerkungs- oder Kennzeichnungsprojekte durchzuführen. Hier gibt es eine Art Mittelweg, in dem Unternehmen nicht alles von Grund auf neu erstellen, sondern auch vermeiden, sich zu sehr auf kommerzielle Anbieter zu verlassen.
Die Do-it-yourself-Mentalität von Open Source ist selbst eine Art Kompromiss – Ingenieure und interne Leute können die Open-Source-Community nutzen, in der dezentrale Benutzerbasen ihre eigene Art von Basisunterstützung bieten. Es wird nicht so sein, wie Sie es von einem Anbieter bekommen – Sie erhalten keine rund um die Uhr einfache Hilfe oder Antworten auf Fragen, ohne interne Recherchen durchzuführen – aber der Preis ist niedriger.
Die große Frage also – Wann sollten Sie ein Data-Annotation-Tool kaufen:
Wie bei vielen Arten von High-Tech-Projekten erfordert diese Art der Analyse – wann gebaut und wann gekauft werden soll – engagiertes Nachdenken und Überlegen, wie diese Projekte beschafft und verwaltet werden. Die Herausforderungen, denen sich die meisten Unternehmen im Zusammenhang mit KI/ML-Projekten gegenübersehen, wenn sie die Option „Build“ in Betracht ziehen, besteht darin, dass es nicht nur um den Bau- und Entwicklungsabschnitt des Projekts geht. Es gibt oft eine enorme Lernkurve, um überhaupt an den Punkt zu gelangen, an dem eine echte KI/ML-Entwicklung stattfinden kann. Bei neuen KI/ML-Teams und -Initiativen überwiegt die Zahl der „unbekannten Unbekannten“ bei weitem die Zahl der „bekannten Unbekannten“.
| Bauen | Kaufen |
|---|---|
Vorteile:
| Vorteile:
|
Nachteile:
| Nachteile:
|
Um es noch einfacher zu machen, bedenken Sie die folgenden Aspekte:
- wenn Sie mit riesigen Datenmengen arbeiten
- wenn Sie mit unterschiedlichen Datentypen arbeiten
- wenn sich die mit Ihren Modellen oder Lösungen verbundenen Funktionalitäten in Zukunft ändern oder weiterentwickeln könnten
- wenn Sie einen vagen oder generischen Anwendungsfall haben
- wenn Sie eine klare Vorstellung von den Kosten benötigen, die mit der Bereitstellung eines Datenanmerkungstools verbunden sind
- und wenn Sie nicht die richtigen Mitarbeiter oder qualifizierten Experten haben, um an den Tools zu arbeiten und eine minimale Lernkurve suchen
Wenn Ihre Antworten diesen Szenarien entgegengesetzt waren, sollten Sie sich auf die Entwicklung Ihres Tools konzentrieren.
So wählen Sie das richtige Datenanmerkungstool für Ihr Projekt aus
Wenn Sie dies lesen, klingen diese Ideen aufregend und sind definitiv leichter gesagt als getan. Wie kann man also die Fülle bereits vorhandener Datenannotationstools nutzen? Im nächsten Schritt werden daher die Faktoren berücksichtigt, die mit der Auswahl des richtigen Datenannotationstools verbunden sind.
Im Gegensatz zu vor ein paar Jahren hat sich der Markt heute mit Tonnen von Datenannotationstools in der Praxis weiterentwickelt. Unternehmen haben mehr Möglichkeiten bei der Auswahl einer basierend auf ihren unterschiedlichen Bedürfnissen. Aber jedes einzelne Tool hat seine eigenen Vor- und Nachteile. Um eine weise Entscheidung treffen zu können, muss neben subjektiven Anforderungen auch ein objektiver Weg beschritten werden.
Schauen wir uns einige der entscheidenden Faktoren an, die Sie dabei berücksichtigen sollten.
Definieren Ihres Anwendungsfalls
Um das richtige Datenannotationstool auszuwählen, müssen Sie Ihren Anwendungsfall definieren. Sie sollten wissen, ob Ihre Anforderung Text, Bild, Video, Audio oder eine Mischung aus allen Datentypen umfasst. Es gibt eigenständige Tools, die Sie kaufen können, und es gibt ganzheitliche Tools, mit denen Sie verschiedene Aktionen an Datensätzen ausführen können.
Die Tools sind heute intuitiv und bieten Ihnen Optionen in Bezug auf Speichermöglichkeiten (Netzwerk, lokal oder Cloud), Anmerkungstechniken (Audio, Bild, 3D und mehr) und viele andere Aspekte. Sie können ein Werkzeug basierend auf Ihren spezifischen Anforderungen auswählen.
Etablierung von Qualitätskontrollstandards
 Dies ist ein entscheidender Faktor, den Sie berücksichtigen sollten, da der Zweck und die Effizienz Ihrer KI-Modelle von den von Ihnen festgelegten Qualitätsstandards abhängen. Wie bei einem Audit müssen Sie Qualitätsprüfungen der von Ihnen eingegebenen Daten und der erhaltenen Ergebnisse durchführen, um zu verstehen, ob Ihre Modelle richtig und für die richtigen Zwecke trainiert werden. Die Frage ist jedoch, wie wollen Sie Qualitätsstandards etablieren?
Dies ist ein entscheidender Faktor, den Sie berücksichtigen sollten, da der Zweck und die Effizienz Ihrer KI-Modelle von den von Ihnen festgelegten Qualitätsstandards abhängen. Wie bei einem Audit müssen Sie Qualitätsprüfungen der von Ihnen eingegebenen Daten und der erhaltenen Ergebnisse durchführen, um zu verstehen, ob Ihre Modelle richtig und für die richtigen Zwecke trainiert werden. Die Frage ist jedoch, wie wollen Sie Qualitätsstandards etablieren?
Wie bei vielen verschiedenen Arten von Jobs können viele Leute Daten annotieren und markieren, aber sie tun dies mit unterschiedlichem Erfolg. Wenn Sie einen Service anfordern, überprüfen Sie nicht automatisch das Niveau der Qualitätskontrolle. Deshalb variieren die Ergebnisse.
Möchten Sie also ein Konsensmodell einsetzen, bei dem Annotatoren Feedback zur Qualität geben und Korrekturmaßnahmen sofort ergriffen werden? Oder bevorzugen Sie Musterprüfungen, Goldstandards oder Schnittmengen gegenüber Unionsmodellen?
Der beste Einkaufsplan stellt sicher, dass die Qualitätskontrolle von Anfang an erfolgt, indem Standards festgelegt werden, bevor ein endgültiger Vertrag vereinbart wird. Dabei sollten Sie auch Fehlermargen nicht übersehen. Manuelle Eingriffe lassen sich nicht vollständig vermeiden, da Systeme mit einer Fehlerquote von bis zu 3% zwangsläufig auftreten. Das kostet zwar Arbeit im Vorfeld, aber es lohnt sich.
Wer wird Ihre Daten kommentieren?
Der nächste wichtige Faktor hängt davon ab, wer Ihre Daten annotiert. Beabsichtigen Sie ein internes Team zu haben oder möchten Sie es lieber auslagern? Wenn Sie auslagern, müssen Sie aufgrund der Datenschutz- und Vertraulichkeitsbedenken im Zusammenhang mit Daten rechtliche und Compliance-Maßnahmen berücksichtigen. Und wenn Sie ein internes Team haben, wie effizient sind sie beim Erlernen eines neuen Tools? Was ist Ihre Time-to-Market mit Ihrem Produkt oder Ihrer Dienstleistung? Verfügen Sie über die richtigen Qualitätskennzahlen und Teams, um die Ergebnisse zu genehmigen?
Der Verkäufer vs. Partnerdebatte
 Die Datenannotation ist ein kollaborativer Prozess. Es beinhaltet Abhängigkeiten und Feinheiten wie Interoperabilität. Dies bedeutet, dass bestimmte Teams immer zusammen arbeiten und eines der Teams Ihr Anbieter sein könnte. Aus diesem Grund ist der von Ihnen ausgewählte Anbieter oder Partner genauso wichtig wie das Tool, das Sie für die Datenkennzeichnung verwenden.
Die Datenannotation ist ein kollaborativer Prozess. Es beinhaltet Abhängigkeiten und Feinheiten wie Interoperabilität. Dies bedeutet, dass bestimmte Teams immer zusammen arbeiten und eines der Teams Ihr Anbieter sein könnte. Aus diesem Grund ist der von Ihnen ausgewählte Anbieter oder Partner genauso wichtig wie das Tool, das Sie für die Datenkennzeichnung verwenden.
Mit diesem Faktor sollten Aspekte wie die Fähigkeit, Ihre Daten und Absichten vertraulich zu behandeln, die Absicht, Feedback anzunehmen und daran zu arbeiten, proaktiv in Bezug auf Datenanforderungen, Flexibilität im Betrieb und mehr berücksichtigt werden, bevor Sie einem Anbieter oder Partner die Hand geben . Wir haben Flexibilität aufgenommen, da die Anforderungen an die Datenannotation nicht immer linear oder statisch sind. Sie können sich in Zukunft ändern, wenn Sie Ihr Geschäft weiter skalieren. Wenn Sie derzeit nur mit textbasierten Daten arbeiten, möchten Sie möglicherweise Audio- oder Videodaten beim Skalieren mit Anmerkungen versehen, und Ihr Support sollte bereit sein, seinen Horizont mit Ihnen zu erweitern.
Beteiligung des Anbieters
Eine Möglichkeit zur Bewertung der Anbieterbeteiligung ist die Unterstützung, die Sie erhalten.
Jeder Kaufplan muss diese Komponente berücksichtigen. Wie wird die Unterstützung vor Ort aussehen? Wer werden die Stakeholder und Point People auf beiden Seiten der Gleichung sein?
Es gibt auch konkrete Aufgaben, die klar machen müssen, was die Beteiligung des Anbieters ist (oder sein wird). Wird der Anbieter insbesondere bei einem Datenannotations- oder Datenkennzeichnungsprojekt die Rohdaten aktiv bereitstellen oder nicht? Wer wird als Fachexperten fungieren und wer wird sie entweder als Angestellte oder als unabhängige Auftragnehmer beschäftigen?
Fallstudien
Hier sind einige konkrete Fallstudienbeispiele, die sich damit befassen, wie Datenannotation und Datenkennzeichnung vor Ort wirklich funktionieren. Bei Shaip achten wir auf höchste Qualität und hervorragende Ergebnisse bei der Datenannotation und Datenbeschriftung.
Ein Großteil der obigen Diskussion über Standardleistungen für Datenannotation und Datenkennzeichnung zeigt, wie wir jedes Projekt angehen und was wir den Unternehmen und Interessengruppen bieten, mit denen wir zusammenarbeiten.
Fallstudienmaterialien, die zeigen, wie dies funktioniert:

In einem Lizenzierungsprojekt für klinische Daten verarbeitete das Shaip-Team über 6,000 Stunden Audio, entfernte alle geschützten Gesundheitsinformationen (PHI) und hinterließ HIPAA-konforme Inhalte für Spracherkennungsmodelle im Gesundheitswesen.
In diesem Fall sind es die Kriterien und die Einstufung von Leistungen, die wichtig sind. Die Rohdaten liegen in Form von Audio vor, und es besteht die Notwendigkeit, Parteien zu de-identifizieren. Bei der Verwendung der NER-Analyse beispielsweise besteht das doppelte Ziel darin, den Inhalt zu de-identifizieren und zu kommentieren.
Eine weitere Fallstudie beinhaltet eine eingehende Konversations-KI-Trainingsdaten Projekt, das wir mit 3,000 Linguisten über einen Zeitraum von 14 Wochen abgeschlossen haben. Dies führte zur Produktion von Trainingsdaten in 27 Sprachen, um mehrsprachige digitale Assistenten zu entwickeln, die in der Lage sind, menschliche Interaktionen in einer breiten Auswahl an Muttersprachen zu bewältigen.
In dieser speziellen Fallstudie war die Notwendigkeit offensichtlich, die richtige Person auf den richtigen Lehrstuhl zu bringen. Die große Zahl von Fachexperten und Operatoren für die Inhaltseingabe erforderte eine organisatorische und prozessuale Optimierung, um das Projekt in einem bestimmten Zeitplan zu erledigen. Unser Team konnte durch die Optimierung der Datenerhebung und der Folgeprozesse den Industriestandard bei weitem übertreffen.
Andere Arten von Fallstudien umfassen Dinge wie Bot-Training und Textannotation für maschinelles Lernen. Auch in einem Textformat ist es immer noch wichtig, identifizierte Parteien gemäß den Datenschutzgesetzen zu behandeln und die Rohdaten zu sortieren, um die gewünschten Ergebnisse zu erzielen.
Mit anderen Worten, bei der Arbeit mit mehreren Datentypen und -formaten hat Shaip den gleichen entscheidenden Erfolg gezeigt, indem er die gleichen Methoden und Prinzipien sowohl auf Rohdaten- als auch auf Datenlizenzierungs-Geschäftsszenarien anwendet.