Computer Vision ist ein riesiges Thema und für Techpreneure und angehende Unternehmer ist es nicht möglich, sich in kurzer Zeit vollständig damit auszukennen. Insbesondere wenn sie ein auf Computer Vision basierendes Produkt entwickeln und nur eine begrenzte Zeit zur Markteinführung haben, benötigen sie umfangreiches und substanzielles Wissen über die Grundlagen von Computer Vision und Bildannotation, um über funktionale Kenntnisse zu verfügen und fundierte Entscheidungen zu treffen.
Dieser Leitfaden wählt Konzepte aus und präsentiert sie auf die einfachste Art und Weise, damit Sie eine gute Klarheit darüber haben, worum es geht. Es hilft Ihnen, eine klare Vorstellung davon zu haben, wie Sie Ihr Produkt entwickeln können, welche Prozesse dahinter stecken, welche technischen Details erforderlich sind und vieles mehr. Dieser Leitfaden ist also äußerst einfallsreich, wenn Sie:
Einleitung
Haben Sie in letzter Zeit Google Lens verwendet? Nun, wenn Sie es nicht getan haben, werden Sie feststellen, dass die Zukunft, auf die wir alle gewartet haben, endlich da ist, wenn Sie beginnen, ihre wahnsinnigen Fähigkeiten zu erkunden. Die Entwicklung von Google Lens ist ein einfaches, ergänzendes Feature des Android-Ökosystems und beweist, wie weit wir in Bezug auf technologischen Fortschritt und Evolution gekommen sind.
Von der Zeit an, als wir nur auf unsere Geräte starrten und nur eine einseitige Kommunikation erlebten – vom Menschen bis zur Maschine, haben wir jetzt den Weg für eine nichtlineare Interaktion geebnet, bei der Geräte uns direkt anstarren, analysieren und verarbeiten können, was sie darin sehen Echtzeit.
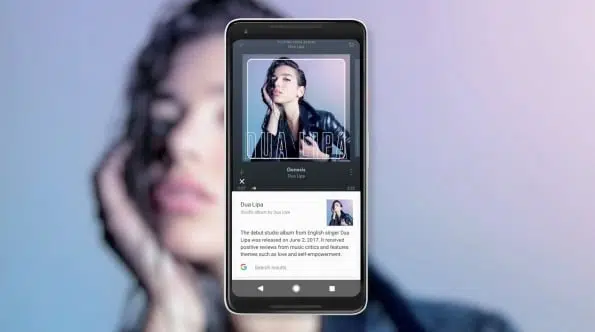
Sie nennen es Computer Vision und es dreht sich alles darum, was ein Gerät aus dem, was es durch seine Kamera sieht, verstehen und die Elemente der realen Welt verstehen kann. Um auf die Großartigkeit von Google Lens zurückzukommen, können Sie Informationen zu zufälligen Objekten und Produkten finden. Wenn Sie die Kamera Ihres Geräts einfach auf eine Maus oder eine Tastatur richten, sagt Ihnen Google Lens die Marke, das Modell und den Hersteller des Geräts.
Außerdem können Sie es auch auf ein Gebäude oder einen Ort zeigen und Details dazu in Echtzeit abrufen. Sie könnten Ihr mathematisches Problem scannen und Lösungen dafür finden, handschriftliche Notizen in Text umwandeln, Pakete durch einfaches Scannen verfolgen und mehr mit Ihrer Kamera tun, ohne jegliche Schnittstelle.
Computer Vision endet hier nicht. Sie hätten es auf Facebook gesehen, wenn Sie versuchen, ein Bild in Ihr Profil hochzuladen, und Facebook erkennt und markiert automatisch Gesichter von Ihnen und denen Ihrer Freunde und Familie. Computer Vision verbessert den Lebensstil der Menschen, vereinfacht komplexe Aufgaben und macht das Leben der Menschen einfacher.

Bildanmerkung für Computer Vision
![]() Bildannotation ist eine Teilmenge der Datenbeschriftung, die auch unter dem Namen Image-Tagging, Transkription oder Beschriftung bekannt ist. Bei der Bildannotation sind Menschen am Backend beteiligt, die unermüdlich Bilder mit Metadateninformationen und Attributen versehen, die Maschinen helfen, Objekte besser zu identifizieren.
Bildannotation ist eine Teilmenge der Datenbeschriftung, die auch unter dem Namen Image-Tagging, Transkription oder Beschriftung bekannt ist. Bei der Bildannotation sind Menschen am Backend beteiligt, die unermüdlich Bilder mit Metadateninformationen und Attributen versehen, die Maschinen helfen, Objekte besser zu identifizieren.

Bildklassifizierung

Der einfachste Typ, bei dem Objekte grob klassifiziert werden. Hier besteht der Prozess also nur darin, Elemente wie Fahrzeuge, Gebäude und Ampeln zu identifizieren.
Objekterkennung

Eine etwas spezifischere Funktion, bei der verschiedene Objekte identifiziert und kommentiert werden. Fahrzeuge können Autos und Taxis, Gebäude und Wolkenkratzer sowie die Spuren 1, 2 oder mehr sein.
Bildsegmentierung

Dies geht auf die Besonderheiten jedes Bildes ein. Es beinhaltet das Hinzufügen von Informationen über ein Objekt, dh Farbe, Standorterscheinung usw., um Maschinen bei der Unterscheidung zu helfen. Das Fahrzeug in der Mitte wäre beispielsweise ein gelbes Taxi auf Spur 2.
Objektüberwachung

Dabei werden die Details eines Objekts wie Standort und andere Attribute über mehrere Frames im selben Datensatz identifiziert. Filmmaterial von Videos und Überwachungskameras kann für Objektbewegungen und Untersuchungsmuster verfolgt werden.
Begrenzungsrahmen

Bei der grundlegendsten Bildannotationstechnik zeichnen Experten oder Kommentatoren einen Rahmen um ein Objekt, um objektspezifische Details zuzuordnen. Diese Technik ist am besten geeignet, um Objekte mit symmetrischer Form mit Anmerkungen zu versehen.
Eine weitere Variation von Bounding Boxes sind Quader. Dies sind 3D-Varianten von Bounding Boxes, die normalerweise zweidimensional sind. Quader verfolgen Objekte über ihre Dimensionen, um genauere Details zu erhalten. Wenn Sie das obige Bild betrachten, könnten die Fahrzeuge leicht durch Begrenzungsrahmen kommentiert werden.
Um Ihnen eine bessere Vorstellung zu geben, geben Ihnen 2D-Boxen Details zur Länge und Breite eines Objekts. Die Quadertechnik gibt Ihnen jedoch auch Details zur Tiefe des Objekts. Das Annotieren von Bildern mit Quadern wird schwieriger, wenn ein Objekt nur teilweise sichtbar ist. In solchen Fällen approximieren Annotatoren die Kanten und Ecken eines Objekts basierend auf vorhandenen Bildern und Informationen.
Sehenswürdigkeiten

Diese Technik wird verwendet, um die Feinheiten der Bewegungen von Objekten in einem Bild oder Filmmaterial hervorzuheben. Sie können auch verwendet werden, um kleine Objekte zu erkennen und zu beschriften. Landmarking wird speziell verwendet in Gesichtserkennung zu kommentierten Gesichtszügen, Gesten, Mimik, Körperhaltung und mehr. Es beinhaltet die individuelle Identifizierung von Gesichtsmerkmalen und deren Attributen, um genaue Ergebnisse zu erzielen.
Um Ihnen ein praktisches Beispiel dafür zu geben, wo Landmarking nützlich ist, denken Sie an Ihre Instagram- oder Snapchat-Filter, die Hüte, Schutzbrillen oder andere lustige Elemente basierend auf Ihren Gesichtszügen und Ausdrücken genau platzieren. Wenn Sie also das nächste Mal für einen Hundefilter posieren, sollten Sie verstehen, dass die App Ihre Gesichtszüge für präzise Ergebnisse markiert hat.
Polygone

Objekte in Bildern sind nicht immer symmetrisch oder regelmäßig. Es gibt unzählige Fälle, in denen Sie feststellen, dass sie unregelmäßig oder einfach nur zufällig sind. In solchen Fällen setzen Annotatoren die Polygontechnik ein, um unregelmäßige Formen und Objekte präzise mit Anmerkungen zu versehen. Diese Technik beinhaltet das Platzieren von Punkten über die Abmessungen eines Objekts und das manuelle Zeichnen von Linien entlang des Umfangs oder Umfangs des Objekts.
Linien

Neben Grundformen und Polygonen werden auch einfache Linien zur Beschriftung von Objekten in Bildern verwendet. Diese Technik ermöglicht es Maschinen, Grenzen nahtlos zu erkennen. Beispielsweise werden für Maschinen in autonomen Fahrzeugen Linien über Fahrspuren gezogen, um die Grenzen, innerhalb derer sie manövrieren müssen, besser zu verstehen. Linien werden auch verwendet, um diese Maschinen und Systeme für verschiedene Szenarien und Umstände zu trainieren und ihnen zu helfen, bessere Fahrentscheidungen zu treffen.




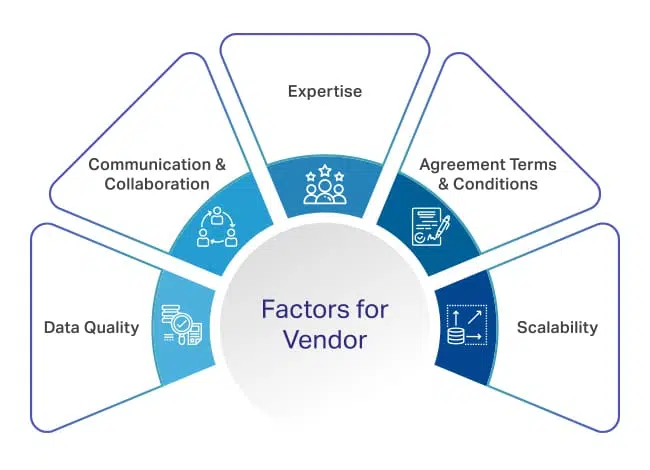
Faktoren, die bei der Auswahl eines Anbieters von Datenanmerkungen zu berücksichtigen sind
Dies ist eine große Verantwortung und die gesamte Leistung Ihres Machine Learning-Moduls hängt von der Qualität der von Ihrem Anbieter gelieferten Datensätze und dem Timing ab. Deshalb sollten Sie vor der Vertragsunterzeichnung mehr darauf achten, mit wem Sie sprechen, was sie versprechen und weitere Faktoren berücksichtigen.
Um Ihnen den Einstieg zu erleichtern, sind hier einige entscheidende Faktoren, die Sie berücksichtigen sollten.