


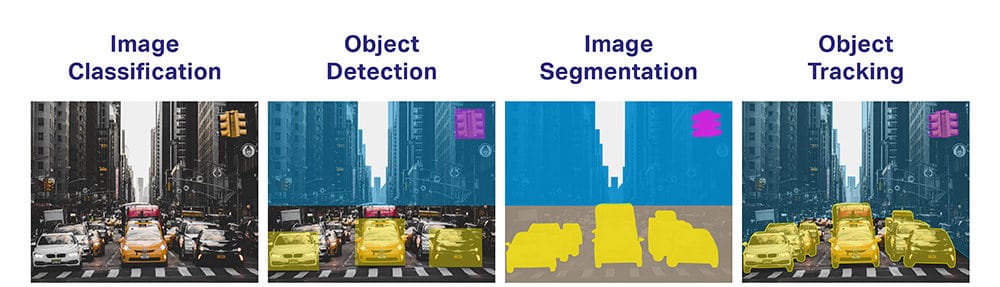
- Objektklassifizierung: Welche breite Kategorie von Objekten gibt es?
- Objektidentifikation: Welche Arten eines bestimmten Objekts gibt es?
- Objektverifizierung: Welches ist das Objekt auf dem Foto?
- Objekterkennung: Wo sind die Objekte auf dem Foto?
- Erkennung von Objektmarkierungen: Was sind die Schlüsselpunkte für das Objekt auf dem Foto?
- Objektsegmentierung: Welche Pixel gehören zum Objekt im Bild?
- Objekterkennung: Welche Objekte sind auf diesem Foto zu sehen und wo sind sie?

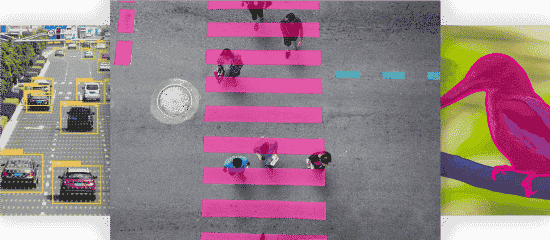


Bildersammlung

Video-Sammlung

Begrenzungsrahmen

3D-Quader
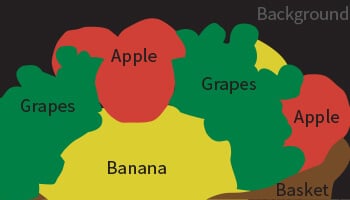
Semantische Segmentierung

Polygon-Anmerkung

Wahrzeichen-Anmerkung

Liniensegmentierung

Bildtranskription
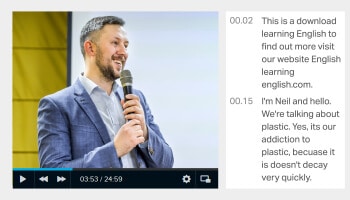
Video Transcription

Bildklassifizierung
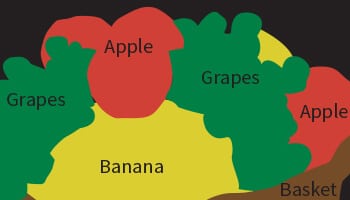
Bildsegmentierung

Bild-Keypoint-Anmerkung

Videoklassifizierung
Videosegmentierung

- Anwendungsfall: ADAS-Modell im Auto
- Format: Bilder
- Volumen: 455,000+
- Anmerkung: Nein

- Anwendungsfall: Erkennung von Wahrzeichen
- Format: Bilder
- Volumen: 80,000+
- Anmerkung: Nein

- Anwendungsfall: Fußgängerverfolgung
- Format: Videos
- Volumen: 84,500+
- Anmerkung: Ja

- Anwendungsfall: Anerkennung von Lebensmitteln
- Format: Bilder
- Volumen: 55,000+
- Anmerkung: Ja

Gesundheitswesen AI
Trainieren Sie ML-Modelle, um Krebsmole in Hautbildern zu erkennen oder Symptome in MRT-Scans oder Röntgenaufnahmen des Patienten zu finden.

Gesichtserkennung
Trainieren Sie ML-Modelle, um Bilder von Personen anhand von Gesichtsmerkmalen zu identifizieren und vergleichen Sie sie mit einer Datenbank mit Gesichtsprofilen, um Personen zu erkennen und zu markieren.

Geoinformationsanwendungen
Annotation von Satellitenbildern und UAV-Fotografie zur Vorbereitung von Datensätzen für die Geoverarbeitung und Annotation von 3D-Punktwolken für Geo.AI.

Erweiterte Realität
Platzieren Sie mit AR-Headset virtuelle Objekte in der realen Welt. Es kann ebene Oberflächen wie Wände, Tischplatten und Böden erkennen - ein sehr wichtiger Bestandteil bei der Bestimmung von Tiefe und Abmessungen und der Platzierung virtueller Objekte in der physischen Welt.

Self-Driving Cars
Mehrere Kameras nehmen Videos aus einem anderen Blickwinkel auf, um die Grenzen von Verkehrssignalen, Straßen, Autos, Objekten und Fußgängern in der Nähe zu erkennen, um den selbstfahrenden Autos beizubringen, das Fahrzeug automatisch zu lenken und das Aufprallen von Hindernissen zu vermeiden, während der Passagier sicher fährt.

Einzelhandel / E-Commerce
Mit Computer Vision im Einzelhandel können die Anwendungen personalisierte Empfehlungen basierend auf dem Kaufverhalten der Kunden anbieten und Geschäftsvorgänge wie Regalverwaltung, Zahlungen usw. beschleunigen.




Personen
Engagierte und geschulte Teams:
- 30,000+ Mitarbeiter für Datenerstellung, Kennzeichnung und QA
- Zertifiziertes Projektmanagement-Team
- Erfahrenes Produktentwicklungsteam
- Talentpool-Sourcing- und Onboarding-Team

Prozess
Höchste Prozesseffizienz wird gewährleistet durch:
- Robuster 6-Sigma-Stage-Gate-Prozess
- Ein engagiertes Team von 6 Sigma Black Belts – Key Process Owners & Quality Compliance
- Kontinuierliche Verbesserung und Feedbackschleife

Plattform
Die patentierte Plattform bietet Vorteile:
- Webbasierte End-to-End-Plattform
- Einwandfreie Qualität
- Schnellere TAT
- Nahtlose Lieferung
Personen
Engagierte und geschulte Teams:
- 30,000+ Mitarbeiter für Datenerstellung, Kennzeichnung und QA
- Zertifiziertes Projektmanagement-Team
- Erfahrenes Produktentwicklungsteam
- Talentpool-Sourcing- und Onboarding-Team
Prozess
Höchste Prozesseffizienz wird gewährleistet durch:
- Robuster 6-Sigma-Stage-Gate-Prozess
- Ein engagiertes Team von 6 Sigma Black Belts – Key Process Owners & Quality Compliance
- Kontinuierliche Verbesserung und Feedbackschleife
Plattform
Die patentierte Plattform bietet Vorteile:
- Webbasierte End-to-End-Plattform
- Einwandfreie Qualität
- Schnellere TAT
- Nahtlose Lieferung