

Die Qualität und Genauigkeit der Ergebnisse eines Gesichts- und Emotionserkennungssystems hängt von den Daten ab. Je genauer und umfangreicher die Daten sind, desto besser sind die Chancen eines KI-Programms, Emotionen zu erkennen und zu erkennen.

Künstliche Intelligenz hat für die Versicherungsbranche einige weitreichende Vorteile, sofern die Unternehmen ihre Umsetzung verstehen. Wenn Aufgaben wie Schadensbearbeitung, Prämienfestlegung und Schadenserkennung optimiert werden, kann dies auch den Kundenservice unterstützen und die Gesamtzufriedenheit steigern.

Die Anonymisierung von Daten ist für den Schutz personenbezogener Daten im Gesundheitswesen von entscheidender Bedeutung und steht im Einklang mit gesetzlichen Anforderungen wie HIPAA und DSGVO. Die vorgestellten Tools, darunter IBM InfoSphere Optim, Google Healthcare API, AWS Comprehend Medical, Shaip und Private-AI, bieten vielfältige Lösungen für eine effektive Datenmaskierung.

Generative KI verfügt über einige leistungsstarke Features und Funktionalitäten, mit denen die Supportsysteme für den Kundendienst überarbeitet werden sollen. Da die generative KI die Probleme des Kunden umgehend lösen kann, kann sie auch Agenten als Ersthelfer ersetzen und wie ein Mensch mit den Kunden kommunizieren.

Die Anonymisierung von Daten ist ein entscheidendes Verfahren zur Gewährleistung des Schutzes vor unbefugtem Zugriff und unrechtmäßiger Nutzung personenbezogener Daten. Dieser Prozess ist besonders wichtig für Gesundheitsdaten und stellt sicher, dass keine persönlich identifizierbaren Informationen in die Hände anderer Personen gelangen als denen, die in engem Zusammenhang mit den Daten stehen.

Konversationelle und generative KI verändern unsere Welt auf einzigartige Weise. Konversations-KI macht das Sprechen mit Maschinen einfach und hilfreich und verbessert den Kundensupport und die Gesundheitsdienste. Generative KI hingegen ist ein kreatives Kraftpaket. Es erfindet neue, originelle Inhalte in den Bereichen Kunst, Musik und mehr. Das Verständnis dieser KI-Typen ist der Schlüssel für intelligente Geschäfts-, Ethik- und Innovationsentscheidungen.

Sprachtechnologien sind noch relativ neue Technologien und wir arbeiten immer noch daran, die damit angebotenen Lösungen gut zu verstehen. In einem zeitkritischen Gesundheitsumfeld sind Effizienz und Genauigkeit von größter Bedeutung.

Generative KI verändert die Landschaft der Bank- und Finanzdienstleistungen, führt zu Effizienzsteigerungen, erhöht die Sicherheit und bietet personalisierte Erlebnisse für Kunden und Institutionen. Da die Technologie weiter voranschreitet, dürfte ihr Einfluss auf die Finanzbranche zunehmen und eine neue Ära der Innovation und Optimierung einläuten.

Der Einsatz von Natural Language Processing (NLP) im Gesundheitswesen und in der Pharmaindustrie basiert stark auf der Analyse unstrukturierter Daten. Mit relevanten Informationen können Gesundheitsorganisationen mehrere Vorteile erzielen und den Patienten bessere Gesundheitsdienstleistungen bieten.

Quantität und Häufigkeit nutzergenerierter Inhalte werden in den kommenden Jahren zunehmen. Kunden haben heute Zugang zu innovativen Tools, die es ihnen ermöglichen, alles über eine Marke zu erfahren. Während die Interaktion mit bestehenden, neuen und potenziellen Kunden für eine Marke von entscheidender Bedeutung ist, ist die Überwachung und Moderation von Inhalten von entscheidender Bedeutung für die Schaffung eines positiven Images.

Eine effektive Datenkennzeichnung ist ein entscheidender Faktor für die Verbesserung der Suchrelevanz. E-Commerce-Plattformen und -Unternehmen profitieren am meisten von der Datenkennzeichnung, da sie ihre Produkte in den Suchergebnissen anzeigen müssen, was zu einer Steigerung von Umsatz und Umsatz führt.

Die Verarbeitung natürlicher Sprache (NLP) hat in allen Branchen eine Revolution bei der Informationsextraktion und -analyse eingeleitet. Auch die Vielseitigkeit dieser Technologie entwickelt sich weiter, um bessere Lösungen und neue Anwendungen zu liefern. Der Einsatz von NLP im Finanzwesen ist nicht auf die oben genannten Anwendungen beschränkt. Mit der Zeit können wir diese Technologie und ihre Techniken für noch komplexere Aufgaben und Vorgänge nutzen.

Im Mittelpunkt der Anwendungen von KI im Gesundheitswesen stehen Daten und deren korrekte Analyse. Mithilfe dieser von medizinischen Fachkräften bereitgestellten Daten und Informationen sind KI-Tools und -Technologien in der Lage, bessere Gesundheitslösungen in Bezug auf Diagnose, Behandlung, Vorhersage, Verschreibung und Bildgebung bereitzustellen.

Die Erkennung benannter Entitäten ist eine wichtige Technik, die den Weg für ein fortgeschrittenes maschinelles Verständnis des Textes ebnet. Obwohl Open-Source-Datensätze Vor- und Nachteile haben, sind sie für das Training und die Feinabstimmung von NER-Modellen von entscheidender Bedeutung. Eine sinnvolle Auswahl und Anwendung dieser Ressourcen kann die Ergebnisse von NLP-Projekten erheblich verbessern.

Generative KI bietet mit ihrer Fähigkeit, vielfältige Inhalte zu erstellen, bemerkenswerte Vorteile wie Effizienz, Skalierbarkeit und Personalisierung. Herausforderungen wie Qualitätskontrolle, Kreativitätseinschränkungen und ethische Bedenken erfordern jedoch sorgfältige Aufmerksamkeit.

Generative KI ist ein spannendes Gebiet, das die Grenzen von Technologie und Kreativität neu definiert. Von der Generierung von menschenähnlichem Text über die Erstellung realistischer Bilder bis hin zur Verbesserung der Codeentwicklung und sogar der Simulation einzigartiger Audioausgaben sind die Anwendungen in der realen Welt ebenso vielfältig wie transformativ.

Die Anwendungen von maschinellem Lernen und KI in der klinischen Datenanalyse sind umfangreich und bahnbrechend. Sie bieten ein enormes Potenzial für die Neugestaltung der Patientenversorgung, die Verbesserung der medizinischen Forschung und die Bereitstellung früherer und genauerer Diagnosen.

Shaip steht an der Spitze der Bereitstellung erstklassiger Gesundheits- und medizinischer Daten, die für KI- und maschinelle Lernmodelle (ML) unerlässlich sind. Wenn Sie ein KI-Projekt im Gesundheitswesen starten oder spezifische medizinische Daten benötigen, ist Shaip der perfekte Partner.

Sprachassistenten sind keine Neuheit mehr; Sie werden für unsere täglichen digitalen Interaktionen immer wichtiger. Der Aufstieg des mehrsprachigen Sprachassistenten verspricht einen bedeutenden Fortschritt, der Sprachbarrieren abbaut und eine größere globale Konnektivität fördert.
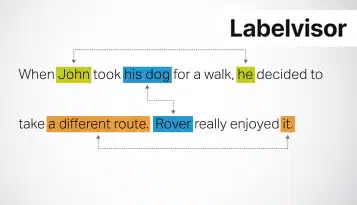
Dokumentanmerkungen sind ein wesentlicher Baustein in den Bereichen KI, maschinelles Lernen und Verarbeitung natürlicher Sprache. Es verbessert das Verständnis und die Verarbeitungsfähigkeiten von KI-Systemen, ermöglicht eine effiziente Informationsextraktion und fördert die Automatisierung in verschiedenen Bereichen.

Wie wir in den obigen Beispielen untersucht haben, birgt die Stimmungsanalyse ein bemerkenswertes Potenzial für eine Vielzahl von Anwendungen, die vom Kundenservice bis zur Politik reichen. Es ermöglicht Unternehmen, das Potenzial subjektiver Daten zu nutzen und unstrukturierten Text in umsetzbare Erkenntnisse umzuwandeln.

Die Zukunft der KI im Gesundheitswesen ist voller Versprechen und Potenzial, wobei die aufkommenden Trends für 2023 einen transformativen Wandel in der Patientenversorgung signalisieren.

Die Anwendungsfälle der Verarbeitung natürlicher Sprache im Gesundheitswesen sind vielfältig und transformativ. Durch die Nutzung der Leistungsfähigkeit von KI, maschinellem Lernen und Konversations-KI revolutioniert NLP die Herangehensweise von Gesundheitsexperten an die Patientenversorgung. Es macht medizinische Arbeitsabläufe effizienter und verbessert die Behandlungsergebnisse insgesamt.
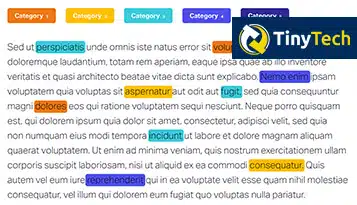
Die Einführung der KI-basierten Entitätsextraktion hat zu erheblichen Fortschritten in verschiedenen Branchen geführt, vom Gesundheitswesen bis zum E-Commerce, zur Verbesserung der Entscheidungsfindung, zur Rationalisierung von Prozessen und zur Verbesserung des Kundenerlebnisses.

Die Emotionserkennungstechnologie ist ein leistungsstarkes Werkzeug, das unser Verständnis menschlicher Emotionen verbessern und uns dabei helfen kann, personalisierte Erfahrungen in verschiedenen Bereichen wie Gesundheitswesen, Bildung und Marketing zu schaffen.

Alles in allem ist das Gesundheitswesen voll von Patienten und Ärzten, die motiviert sind, wieder einen Unterschied im Leben von Menschen auf der ganzen Welt zu machen. Der Zugriff auf große Datenmengen ist eine Einbahnstraße Künstliche Intelligenz wird sich als Zukunft der Medizin weiter beweisen. Es liegt an Forschern und Entwicklern gleichermaßen, diese einzigartigen Datensätze zu nutzen, um unser Verständnis von klinischen Studien und Patientenversorgung zu verbessern, während wir uns auf eine zunehmend vernetzte Zukunft für alle zubewegen.

Die nächsten fünf Jahre werden optimierte KI-Erfahrungen, Sicherheitsfunktionen, die diese Interaktionen verbessern, und mehr bringen. Konversations-KI-Trends in den nächsten Jahren werden heller und zugänglicher sein als je zuvor.

Die Änderungen dauern an und führen zu einer bankfähigeren, profitableren Zukunft, die eine bessere Benutzererfahrung bietet. Mit diesen Veränderungen in Verbindung mit der Fähigkeit, aus den Fehlern anderer Unternehmen zu lernen, wird sich der BFSI-Sektor weiterhin schnell in Richtung Gesichtserkennung bewegen – ein effektiveres und sichereres Endziel für alle beteiligten Stellen.

Die Sprachsuche ist ein aufstrebendes Technologiefeld. Es macht langsam aber sicher riesige Fortschritte, da es mit KI, Verarbeitung natürlicher Sprache und maschinellem Lernen leistungsfähiger wird. Die Art von KI, die es jetzt gibt, ist nicht empfindungsfähig; Diese Sprachassistenten sind Werkzeuge, die unser Leben besser, einfacher und effizienter machen.
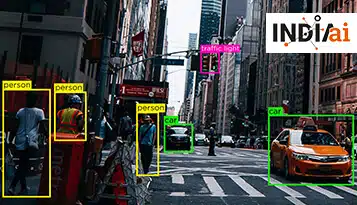
Data Labeling Services helfen Unternehmen dabei, Daten ohne Labels oder Tags in Daten umzuwandeln, die Labels oder Tags haben. Sie verwenden oft eine menschliche Task Force oder maschinelles Lernen, um die Datensätze zu kennzeichnen, die Unternehmen ihnen geben.

Die Spracherkennungstechnologie kann die Gesundheitsbranche in mehrfacher Hinsicht revolutionieren. Durch die Ermöglichung einer schnelleren und genaueren Dokumentation, die Reduzierung des Fehlerrisikos und die Verbesserung der Patientenbindung kann die Spracherkennungstechnologie Gesundheitsdienstleistern helfen, eine qualitativ hochwertigere Versorgung zu gewährleisten.

Die Versicherungsbranche verfügt über viele Daten, die jedoch so unübersichtlich sind, dass eine Suche fast unmöglich ist. Die Versicherungsbranche muss digitalisiert werden – und das kann sie jetzt. Mit OCR wird das Sammeln und Sortieren von Daten so einfach wie das Aufnehmen eines Fotos oder das Eingeben einiger Wörter.

Banken werden positive Erfahrungen mit der Implementierung von KI-Technologien machen. Dies basiert auf Interviews mit Unternehmen, die KI bereits in ihren Geschäftsprozessen einsetzen. Solange Sicherheitsvorkehrungen getroffen werden, um die Sicherheit von Kundendaten und ethische Standards zu gewährleisten, die automatisch reguliert werden können, sollten Banken KI in ihre Systeme implementieren.

Die Auswirkungen des maschinellen Lernens auf dem Call-Center-Markt sind real und messbar. Datenerfassung in Echtzeit und maschinelles Lernen wurden kombiniert, um noch effizientere Callcenter zu ermöglichen. Darüber hinaus haben sprachbasierte Lösungen in ganz Nordamerika zugenommen und verbreiten sich weiterhin auf der ganzen Welt.

Die Spracherkennungstechnologie gewinnt im Gesundheitswesen immer mehr an Bedeutung, da Ärzte und Pflegekräfte sich bei der Erledigung vieler ihrer beruflichen Aufgaben zunehmend darauf verlassen. Obwohl noch viele Fragen zu klären sind, bevor wir eine weit verbreitete Anwendung dieser Technologie in Krankenhäusern, klinischen Umgebungen und Arztpraxen sehen, deuten die ersten Anzeichen auf ein erhebliches Potenzial hin.
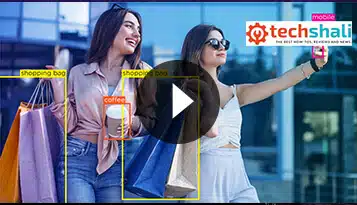
Die Videoannotationstechnologie soll die Sicherheit von KI-Systemen und Kunden im Einzelhandel gewährleisten. Videoanmerkungssoftware ist eine großartige Möglichkeit, dies zu tun, indem sie es den Menschen ermöglicht, die Behörden schnell und einfach zu benachrichtigen, wenn sie etwas Verdächtiges in einer Einzelhandelsumgebung beobachten, und; KI-Systemen dabei zu helfen, aus vergangenen Erfahrungen zu lernen, damit sie ihre Reaktionen darauf abstimmen können, ein besseres Gefühl dafür zu bekommen, was als normales Verhalten gilt.

Anwendungsfälle der Gesichtserkennung können beim Speichern und Abrufen von Daten Wunder bewirken, bringen aber auch ein faszinierendes ethisches Dilemma mit sich. Macht es Sinn, eine solche Technologie einzusetzen? Einige Leute glauben, dass die Antwort „Nein“ lautet, insbesondere im Hinblick auf die Verletzung der Privatsphäre durch die Gesichtserkennung. Andere zitieren die Verwendung dieser neuen Tools, weshalb Sie diese Technologie möglicherweise nicht um jeden Preis vermeiden möchten.

KI wird die Art und Weise verändern, wie wir mit Technologie interagieren. Sobald Sie sich an die Konversations-KI gewöhnt haben und sie zu einem nahtlosen Bestandteil Ihres Lebens geworden ist, werden Sie sich fragen, wie Sie jemals darauf hätten verzichten können.

Benutzerdefinierte Aktivierungswörter können bei der Personalisierung Ihrer Marke helfen und sie von Mitbewerbern abheben. Bei der Auswahl eines benutzerdefinierten Weckworts sind viele Faktoren zu berücksichtigen. Wenn Sie sich jedoch in der heutigen wettbewerbsintensiven Geschäftswelt abheben möchten, lohnt es sich, zusätzliche Anstrengungen zu unternehmen, um sicherzustellen, dass Ihr Sprachassistent einzigartig klingt.

Neue Fortschritte in der Sprachtechnologie sind hier, um zu bleiben. Sie werden immer beliebter und machen jetzt den perfekten Zeitpunkt, um der Kurve voraus zu sein und mit der Entwicklung innovativer Spracherlebnisse für Fahrer zu beginnen. Wenn Autohersteller Spracherkennung in ihre Autos integrieren, eröffnet dies eine neue Welt voller Möglichkeiten für die Technologie und ihre Benutzer.

Es ist klar, dass Lebensmittel-KI einen großen Einfluss darauf haben wird, wie wir uns ernähren. Vom Streben der Fast-Food-Ketten nach anpassbareren Menüs bis hin zu einer Reihe neuer, innovativer Restaurants gibt es unzählige Möglichkeiten für die Technologie, unsere Esserlebnisse zu vereinfachen und die Qualität unserer Lebensmittel zu verbessern. Mit der Weiterentwicklung von künstlicher Intelligenz und maschinellen Lernalgorithmen können wir davon ausgehen, dass sich intelligente Lebensmittel-KI positiv auf unsere Gesundheit und die ökologischen Auswirkungen unseres Ernährungssystems insgesamt auswirkt.

Zusammenfassend lässt sich sagen, dass die semantische Segmentierung ein wichtiger Sektor von Deep-Learning-Algorithmen ist, die genutzt werden, um Fortschritte in der Computer Vision voranzutreiben. Die semantische Segmentierung wird in vielen dieser verwandten Unterkategorien, Objekterkennung, Klassifizierung und Lokalisierung, weiter voranschreiten.

Insgesamt sollte ein effektives Spracherkennungssystem einfach einzurichten und in verschiedenen Situationen zu verwenden sein, während es genaue Ergebnisse mit wenig Frustration auf Seiten des Benutzers erzielt.

Der Aufbau von Smart-Home-Daten erfordert eine Reihe von Prozessen, die am Ende sicherstellen, dass der maschinelle Lernalgorithmus funktioniert und Daten ohne Unterbrechung verarbeitet.

Die Versicherungsbranche ist in Bezug auf technologische Fortschritte traditionell konservativ und zögert, neue Technologien einzuführen. Die Zeiten ändern sich jedoch und künstliche Intelligenz (KI) gewinnt viel Aufmerksamkeit von Versicherungsunternehmen, die beginnen, die wichtige Rolle zu erkennen, die KI in ihrem Betrieb spielen kann.

Die Datenerfassung ist der Prozess des Sammelns, Analysierens und Messens genauer Daten aus verschiedenen Systemen, die für die Entscheidungsfindung von Geschäftsprozessen, Sprachprojekte und Forschung verwendet werden.

Banking ist nicht mehr das, was es einmal war. Die meisten von uns brauchen schnelle, effiziente, fehlerfreie Bankdienstleistungen, die problemlos und vor allem zuverlässig sind. Es ist nur sinnvoll, auf digitale Banking-Kanäle umzusteigen, die diese Dinge bieten können. Wie sich herausstellt, können virtuelle Assistenten mit künstlicher Intelligenz (KI) und maschinellem Lernen (ML) genau das tun.

Mussten Sie schon einmal wichtige E-Mails in eine andere Sprache übersetzen? Wenn ja, werden Sie frustriert sein, wenn Sie wissen, dass jemandes E-Mail-Anrufbeantworter Ihre E-Mails nicht schnell für Sie übersetzen kann. Dies kann besonders frustrierend sein, wenn Kommunikation für eine Organisation von entscheidender Bedeutung ist.

Die Begriffe Chatbot und virtuelle Assistenten werden verwendet, um Konversationen mithilfe von Automatisierungsfunktionen mit menschlicher Note zu erstellen. Mit autonomer Lösung beschleunigen Chatbots und virtuelle Assistenten auch das Mitarbeiter- und Kundenerlebnis.

Eine stark vereinfachte Version der Dokumentenklassifizierung, die oft als eine der Unterdomänen der Textklassifizierung angesehen wird, bedeutet, die Dokumente mit Tags zu versehen und sie direkt in vordefinierte Kategorien einzuordnen – zum Zweck der einfachen Wartung und effizienten Erkennung.

Hey Siri, kannst du mich nach einem guten Blog-Beitrag durchsuchen, der die Top-Trends für Conversational AI auflistet? Oder, Alexa, kannst du mir einfach ein Lied vorspielen, das mich von den alltäglichen Aufgaben ablenkt. Nun, das sind nicht nur Rhetoriken, sondern Standarddiskussionen im Salon, die die Gesamtwirkung eines Konzepts namens Conversational AI validieren.

OCR oder Optical Character Recognition ist eine unterhaltsame Art, Dokumente zu lesen und zu verstehen. Aber warum macht es überhaupt Sinn? Lass es uns herausfinden. Aber bevor wir fortfahren, müssen wir uns mit einem weniger verbreiteten Begriff des maschinellen Lernens befassen: RPA (Robotic Process Automation).

Die harte Wahrheit ist, dass die Qualität Ihrer gesammelten Trainingsdaten die Qualität Ihres Spracherkennungsmodells oder sogar des Geräts bestimmt. Daher ist es notwendig, sich mit erfahrenen Datenanbietern in Verbindung zu setzen, die Ihnen dabei helfen, ohne großen Aufwand durch den Prozess zu navigieren, insbesondere wenn das Trainieren eines Modells oder der betreffenden Algorithmen das Sammeln, Kommentieren und andere geschickte Strategien erfordert.

Die Fähigkeit, die den Maschinen eingeflößt wurde – sie in die Lage zu versetzen, auf möglichst humane Weise zu interagieren – hat eine andere Art von High. Es bleibt jedoch die Frage, wie die Konversations-KI in Echtzeit funktioniert und welche Art von Technologie ihre Existenz antreibt.

Wie der Name schon sagt, handelt es sich bei synthetischen Daten um Daten, die künstlich generiert werden und nicht durch tatsächliche Ereignisse erstellt werden. In den Bereichen Marketing, soziale Medien, Gesundheitswesen, Finanzen und Sicherheit helfen synthetische Daten dabei, innovativere Lösungen zu entwickeln.

Wenn wir über optische Zeichenerkennung (OCR) sprechen, handelt es sich um einen Bereich der künstlichen Intelligenz (KI), der sich speziell auf Computer Vision und Mustererkennung bezieht. OCR bezieht sich auf den Prozess des Extrahierens von Informationen aus mehreren Datenformaten wie Bildern, PDFs, handschriftlichen Notizen und gescannten Dokumenten und deren Umwandlung in ein digitales Format zur weiteren Verarbeitung.

Das Fahrerüberwachungssystem ist ein fortschrittliches Sicherheitsmerkmal, das eine am Armaturenbrett montierte Kamera verwendet, um die Aufmerksamkeit und Schläfrigkeit des Fahrers zu überwachen. Falls der Fahrer schläfrig und abgelenkt wird, erzeugt das Fahrerüberwachungssystem einen Alarm und empfiehlt eine Pause.

Die Verarbeitung natürlicher Sprache ist ein Teilgebiet der künstlichen Intelligenz, das in der Lage ist, die menschliche Sprache aufzuschlüsseln und die Grundsätze derselben an die intelligenten Modelle weiterzugeben. Haben Sie geplant, NLP als Ihre vorbildliche Trainingstechnologie zu verwenden? Lesen Sie weiter, um die Herausforderungen und Lösungen zu ihrer Behebung kennenzulernen.

Darüber hinaus lernt Conversational AI ständig aus früheren Erfahrungen mit maschinellen Lerndatensätzen, um Echtzeit-Einblicke und exzellenten Kundenservice zu bieten. Außerdem versteht und beantwortet Conversational AI unsere Anfragen nicht nur manuell, sondern kann auch mit anderen KI-Technologien wie Suche und Vision verbunden werden, um den Prozess zu beschleunigen.

Bilderkennung ist die Fähigkeit von Software, Objekte, Orte, Personen und Aktionen in Bildern zu identifizieren. Mithilfe von Datensätzen für maschinelles Lernen können Unternehmen mithilfe der Bilderkennung Objekte identifizieren und in mehrere Kategorien einteilen.

Künstliche Intelligenz macht Maschinen intelligenter, Punkt! Die Art und Weise, wie sie es tun, ist jedoch so unterschiedlich und faszinierend wie die betreffende Branche. Zum Beispiel sind Natural Language Processing praktisch, wenn Sie witzige Chatbots und digitale Assistenten entwerfen und entwickeln möchten. Wenn Sie den Versicherungssektor transparenter und benutzerfreundlicher gestalten möchten, ist Computer Vision die KI-Unterdomäne, auf die Sie sich konzentrieren müssen.

Können Maschinen Emotionen erkennen, indem sie einfach das Gesicht scannen? Die gute Nachricht ist, dass sie es können. Und die schlechte Nachricht ist, dass der Markt noch einen langen Weg vor sich hat, bevor er zum Mainstream wird. Die Hindernisse und Herausforderungen bei der Einführung hindern die KI-Evangelisten jedoch nicht daran, „Emotionserkennung“ auf die KI-Landkarte zu setzen – ziemlich aggressiv.

Computer Vision ist nicht so weit verbreitet wie andere KI-Anwendungen wie Natural Language Processing. Dennoch steigt es langsam in den Reihen auf und macht 2022 zu einem aufregenden Jahr für eine breitere Einführung. Hier sind einige der trendigen Computer-Vision-Potenziale (hauptsächlich die Domänen), die von Unternehmen im Jahr 2022 voraussichtlich besser erforscht werden.

Unternehmen auf der ganzen Welt stellen von papierbasierten Dokumenten auf digitale Datenverarbeitung um. Aber was ist OCR? Wie funktioniert es? Und in welchen Geschäftsprozessen kann es eingesetzt werden, um seine Vorteile zu nutzen? Lassen Sie uns in diesem Artikel untersuchen, welche Vorteile OCR mit sich bringt.

Die Antwort lautet Automatische Spracherkennung (ASR). Es ist ein großer Schritt, das gesprochene Wort in geschriebene Form zu überführen. Die automatische Spracherkennung (ASR) ist ein Trend, der 2022 für Aufsehen sorgen wird. Und der Anstieg des Wachstums von Sprachassistenten ist auf integrierte Sprachassistenten-Smartphones und intelligente Sprachgeräte wie Alexa zurückzuführen.
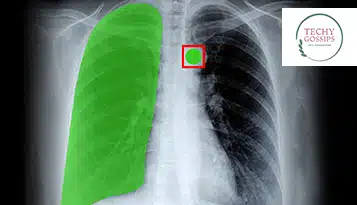
Suchen Sie nach den Köpfen hinter den besten Modellen der künstlichen Intelligenz? Verbeugen Sie sich vor den Data Annotators. Auch wenn die Datenannotation im Mittelpunkt der Vorbereitung von Ressourcen steht, die für jede KI-gesteuerte Branche relevant sind, werden wir das Konzept untersuchen und mehr über die Labeling-Protagonisten aus der Perspektive der KI im Gesundheitswesen erfahren.

Und finden Sie es nicht faszinierend, wenn Käufer die Rechnung an der Kasse bezahlen, indem sie nur ein Gesicht darstellen und nicht irgendeine Karte oder Brieftasche? Die Gesichtserkennung ermöglicht es Einzelhändlern, die Stimmungen und Vorlieben der Käufer auf der Grundlage ihrer vergangenen Einkäufe zu analysieren.

Wie können Finanzunternehmen angesichts der zunehmenden Zahl digitaler Zahlungen auf der ganzen Welt eine maximale Umsatzkonvertierung und Zahlungsakzeptanz sicherstellen und gleichzeitig das Risiko minimieren? Klingt alarmierend? In der Finanzbranche, die in hohem Maße auf Datenverarbeitung und Informationen angewiesen ist, die einen marginalen Vorsprung behalten und die natürlichen Nuancen der Kunden verstehen, um eine pünktliche Lösung bereitzustellen, ist KI-bezogene Technologie erforderlich.

Drohnen sind ein praktikables Werkzeug zur Datenerfassung und liefern Echtzeitinformationen. Die Verwendung von Datenanalysen erleichtert die Inspektion von Brücken, Bergbau und Wettervorhersagen.

Die Call-Center-Stimmungsanalyse ist die Verarbeitung von Daten, indem die natürlichen Nuancen des Kundenkontexts identifiziert und Daten analysiert werden, um den Kundenservice einfühlsamer zu machen.

Nun, der erste Grund braucht keine Bestätigung. Machine-Learning-Projekte erfordern Algorithmen, Datenbeschaffung, hochwertige Annotation und andere komplexe Aspekte, die gut gepflegt werden.

Als Zweig der künstlichen Intelligenz geht es beim NLP darum, Maschinen auf die menschliche Sprache reagieren zu lassen. Was den technischen Aspekt anbelangt, so verwendet NLP ganz passend Informatik, Linguistik, Algorithmen und die allgemeine Sprachstruktur, um die Maschinen intelligent zu machen. Die proaktiven und intuitiven Maschinen, wann immer sie gebaut werden, können die wahre Bedeutung und den Kontext aus Sprache und sogar Text extrahieren, analysieren und verstehen.

Hier spielt die Annotation medizinischer Bilder eine Rolle, da sie den KI-gestützten medizinischen Diagnoseeinrichtungen effizient das erforderliche Wissen vermittelt, um das Vorhandensein einer genauen Computervision als zugrunde liegende Modellentwicklungstechnologie zu fördern.

Künstliche Intelligenz muss kein düsteres Diskussionsthema sein. Voller Möglichkeiten, in den kommenden Jahren das transformativste Werkzeug zu werden, entwickelt sich KI schnell zu einer unterstützenden Ressource, anstatt als überwältigende Technologie auf Kurs zu bleiben.

Kennen Sie die technischen Details, die erforderlich sind, um Machine-Learning-Modelle ganzheitlich, intuitiv und wirkungsvoll zu gestalten? Wenn nicht, müssen Sie zuerst verstehen, wie jeder Prozess grob in drei Phasen unterteilt ist, dh Spaß, Funktionalität und Finesse. Während es bei „Finesse“ darum geht, ML-Algorithmen perfekt zu trainieren, indem zunächst komplexe Programme mit entsprechenden Programmiersprachen entwickelt werden, geht es beim „Fun“-Teil darum, den Kunden mit dem einfühlsamen und intelligenten Spaßprodukt glücklich zu machen.

Stellen Sie sich vor, Sie wachen eines schönen Tages auf und sehen alle Ihre Küchencontainer in Schwarz, was Sie blind macht für das, was sich darin befindet. Und dann wird es eine Herausforderung sein, Zuckerwürfel für Ihren Tee zu finden. Vorausgesetzt, Sie finden den Tee zuerst.

Datenanmerkung ist einfach der Prozess der Kennzeichnung von Informationen, damit Maschinen sie verwenden können. Es ist besonders nützlich für überwachtes maschinelles Lernen (ML), bei dem das System auf gekennzeichnete Datensätze angewiesen ist, um Eingabemuster zu verarbeiten, zu verstehen und daraus zu lernen, um die gewünschten Ausgaben zu erzielen.

Datenkennzeichnung ist nicht allzu schwierig, sagte noch nie eine Organisation! Aber trotz der Herausforderungen auf dem Weg wissen nicht viele, wie anspruchsvoll die anstehenden Aufgaben sind. Die Kennzeichnung von Datensätzen, insbesondere um sie für KI- und Machine-Learning-Modelle geeignet zu machen, erfordert jahrelange Erfahrung und praktische Glaubwürdigkeit. Und zu allem Überfluss ist die Datenbeschriftung kein eindimensionaler Ansatz und variiert je nach Art des in Arbeit befindlichen Modells.

Die Datenerfassung für Sprachprojekte wird durch eine systematische Vorgehensweise vereinfacht. Lesen Sie unseren exklusiven Beitrag zur Datenerfassung für Sprachprojekte und verschaffen Sie sich Klarheit.

Mit einfachen Worten, bei der Textanmerkung geht es darum, bestimmte Dokumente, digitale Dateien und sogar den zugehörigen Inhalt zu kennzeichnen. Sobald diese Ressourcen mit Tags oder Labels versehen sind, werden sie verständlich und können von den maschinellen Lernalgorithmen eingesetzt werden, um die Modelle bis zur Perfektion zu trainieren.

Heute haben wir Vatsal Ghiya für sein Interview ausgewählt. Vatsal Ghiya ist ein Serial Entrepreneur mit mehr als 20 Jahren Erfahrung mit KI-Software und -Dienstleistungen im Gesundheitswesen. Er ist CEO und Mitbegründer von Shaip, das die On-Demand-Skalierung unserer Plattform, Prozesse und Mitarbeiter für Unternehmen mit den anspruchsvollsten Initiativen für maschinelles Lernen und künstliche Intelligenz ermöglicht.

Finanzdienstleistungen haben sich im Laufe der Zeit gewandelt. Der Anstieg bei mobilen Zahlungen, persönlichen Banklösungen, besserer Kreditüberwachung und anderen Finanzmustern stellt außerdem sicher, dass der Bereich der monetären Einschlüsse nicht mehr das ist, was er noch vor einigen Jahren war. Im Jahr 2021 geht es nicht nur um „Fin“ oder Finanzen, sondern um alle „FinTech“ mit disruptiven Finanztechnologien, die sich bemerkbar machen, um das Kundenerlebnis, den Modus Operandi für relevante Organisationen oder um genau zu sein die gesamte Finanzwelt zu verändern.
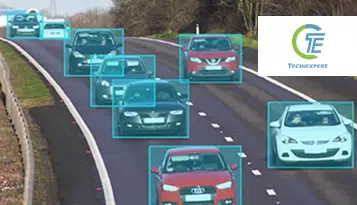
Trotz des rechtzeitigen Aufstiegs der Automobilindustrie lässt die Vertikale viel Spielraum für inkrementelle Verbesserungen. Angefangen von der Verringerung von Verkehrsunfällen bis hin zur Verbesserung der Fahrzeugherstellung und des Ressourceneinsatzes scheint Künstliche Intelligenz die wahrscheinlichste Lösung zu sein, um die Dinge in den Himmel zu bringen.

Künstliche Intelligenz scheint heutzutage eher ein Marketing-Jargon zu sein. Jedes Unternehmen, Startup oder Unternehmen, das Sie kennen, bewirbt seine Produkte und Dienstleistungen jetzt mit dem Begriff "KI-powered" als USP. Getreu dem, künstliche Intelligenz scheint heutzutage unvermeidlich zu sein. Wenn Sie bemerken, wird fast alles, was Sie um sich herum haben, von KI angetrieben. Von den Empfehlungs-Engines auf Netflix und Algorithmen in Dating-Apps bis hin zu einigen der komplexesten Einheiten im Gesundheitswesen, die in der Onkologie helfen, ist künstliche Intelligenz heute der Dreh- und Angelpunkt von allem.

Maschinelles Lernen hat wahrscheinlich die unterschiedlichsten Definitionen und Interpretationen der Welt. Was vor einigen Jahren als Schlagwort aufgetaucht ist, verblüfft noch immer viele Menschen durch die Art und Weise, wie es dargestellt und präsentiert wird.

Künstliche Intelligenz (KI) ist ehrgeizig und für den Fortschritt der Menschheit von immensem Nutzen. Insbesondere in einem Bereich wie dem Gesundheitswesen führt künstliche Intelligenz zu bemerkenswerten Veränderungen in der Art und Weise, wie wir an die Diagnose von Krankheiten, deren Behandlung, Patientenversorgung und Patientenüberwachung herangehen. Nicht zu vergessen die Forschung und Entwicklung, die mit der Entwicklung neuer Medikamente verbunden ist, neuere Möglichkeiten, Bedenken und Grunderkrankungen zu entdecken und vieles mehr.

Das Gesundheitswesen als Branche war nie statisch. Aber andererseits war es noch nie so dynamisch, mit dem Zusammentreffen unterschiedlicher medizinischer Erkenntnisse, die uns dazu bringen, leblos auf Berge unstrukturierter Daten zu starren. Um ehrlich zu sein, ist das gigantische Datenvolumen kein Thema mehr. Es ist eine Realität, die bis Ende 2,000 sogar die 2020-Exabyte-Marke überschritten hat.

Künstliche Intelligenz ist die Technologie, die es Maschinen ermöglicht, menschliches Verhalten nachzuahmen. Es geht darum, Maschinen beizubringen, autonom zu lernen und zu denken und die Ergebnisse zu nutzen, um entsprechend zu reagieren und zu reagieren.

Jedes Mal, wenn Ihr GPS-Navigationssystem Sie auffordert, einen Umweg zu nehmen, um den Verkehr zu vermeiden, sollten Sie sich bewusst sein, dass solche präzisen Analysen und Ergebnisse nach mehreren hundert Stunden Training erzielt werden. Immer wenn Ihre Google Lens-App ein Objekt oder ein Produkt genau identifiziert, sollten Sie wissen, dass Tausende und Abertausende von Bildern von ihrem KI-Modul (Künstliche Intelligenz) zur genauen Identifizierung verarbeitet wurden.

4 Grundlegende Dinge, die Sie über die De-Identifikation von Daten wissen sollten. Da die Datengenerierung täglich 2.5 Trillionen Bytes beträgt, generierten wir als Internetnutzer im Jahr 1.7 jede einzelne Sekunde fast 2020 MB.

Jetzt, da der gesamte Planet online und vernetzt ist, generieren wir kollektiv unermessliche Datenmengen. Eine Branche, ein Unternehmen, ein Marktsegment oder jede andere Einheit würde Daten als eine einzige Einheit betrachten. Dennoch werden Daten, soweit es Einzelpersonen betrifft, besser als unser digitaler Fußabdruck bezeichnet.

Qualitätsdaten führen zu Erfolgsgeschichten, während eine schlechte Datenqualität eine gute Fallstudie darstellt. Einige der wirkungsvollsten Fallstudien zur KI-Funktionalität sind auf einen Mangel an qualitativ hochwertigen Datensätzen zurückzuführen. Während Unternehmen alle von ihren KI-Projekten und -Produkten begeistert und ehrgeizig sind, spiegelt sich die Begeisterung nicht in den Datenerfassungs- und Schulungspraktiken wider. Da sie sich mehr auf den Output als auf die Ausbildung konzentrieren, verzögern einige Unternehmen ihre Markteinführungszeit, verlieren ihre Finanzierung oder ziehen sogar ihre Fensterläden für die Ewigkeit herunter.

Ein Prozess zum Annotieren oder Markieren generierter Daten, der es Algorithmen des maschinellen Lernens und der künstlichen Intelligenz ermöglicht, jeden Datentyp effizient zu identifizieren und zu entscheiden, was daraus gelernt und was damit zu tun ist. Je besser definiert oder beschriftet jeder Datensatz ist, desto besser können die Algorithmen ihn für optimierte Ergebnisse verarbeiten.
Alexa, gibt es einen Sushi-Laden in meiner Nähe? Oft stellen wir unseren virtuellen Assistenten oft offene Fragen. Solche Fragen an Mitmenschen zu stellen, ist verständlich, wenn man bedenkt, dass wir es gewohnt sind, zu sprechen und zu interagieren. Eine umgangssprachlich sehr beiläufige Frage an eine Maschine zu stellen, die kaum Sprach- und Konversationsfeinheiten versteht, macht jedoch keinen Sinn, oder?

Nun, hinter jedem solchen überraschenden Vorfall stecken Konzepte wie künstliche Intelligenz, maschinelles Lernen und vor allem NLP (Natural Language Processing). Einer der größten Durchbrüche unserer letzten Zeit ist NLP, bei dem sich Maschinen allmählich weiterentwickeln, um zu verstehen, wie Menschen sprechen, Emotionen zeigen, verstehen, reagieren, analysieren und sogar menschliche Gespräche und gefühlsgesteuerte Verhaltensweisen nachahmen. Dieses Konzept hat großen Einfluss auf die Entwicklung von Chatbots, Text-to-Speech-Tools, Spracherkennung, virtuellen Assistenten und mehr.

Obwohl es sich um ein in den 1950er Jahren eingeführtes Konzept handelte, wurde Künstliche Intelligenz (KI) erst vor einigen Jahren zu einem Begriff. Die Entwicklung der KI verlief schrittweise und es hat fast sechs Jahrzehnte gedauert, um die wahnsinnigen Funktionen und Funktionen anzubieten, die sie heute bietet. All dies war aufgrund der gleichzeitigen Entwicklung von Hardware-Peripheriegeräten, technischen Infrastrukturen, verwandten Konzepten wie Cloud-Computing, Datenspeicher- und -verarbeitungssystemen (Big Data und Analytics), der Durchdringung und Kommerzialisierung des Internets und mehr immens möglich. Alles zusammen hat zu dieser erstaunlichen Phase der Tech-Timeline geführt, in der KI und Machine Learning (ML) nicht nur Innovationen vorantreiben, sondern auch zu unvermeidlichen Konzepten werden, ohne die man leben kann.

Jedes KI-System benötigt riesige Mengen an Qualitätsdaten, um zu trainieren und genaue Ergebnisse zu liefern. Nun, es gibt zwei Schlüsselwörter in diesem Satz – riesige Mengen und qualitativ hochwertige Daten. Lassen Sie uns beide einzeln besprechen.

Alle bisherigen Gespräche und Diskussionen über den Einsatz künstlicher Intelligenz für Geschäfts- und Betriebszwecke waren nur oberflächlich. Einige sprechen über die Vorteile ihrer Implementierung, während andere darüber diskutieren, wie ein KI-Modul die Produktivität um 40 % steigern kann. Aber die wirklichen Herausforderungen bei deren Einbindung für unsere Geschäftszwecke gehen wir kaum an.
Ohne Technologien wie Künstliche Intelligenz (KI) und Maschinelles Lernen (ML) ist der Kampf gegen eine globale Pandemie kaum vorstellbar. Der exponentielle Anstieg von Covid-19-Fällen auf der ganzen Welt hat viele Gesundheitsinfrastrukturen lahmgelegt. Institutionen, Regierungen und Organisationen konnten sich jedoch mit Hilfe fortschrittlicher Technologien wehren. Künstliche Intelligenz und maschinelles Lernen, einst als Luxus für gehobenen Lebensstil und Produktivität angesehen, sind dank ihrer unzähligen Anwendungen zu lebensrettenden Mitteln bei der Bekämpfung von Covid geworden.

Schmerzen werden bei bestimmten Personengruppen intensiver empfunden. Studien haben gezeigt, dass Personen aus Minderheiten und unterprivilegierten Gruppen aufgrund von Stress, allgemeiner Gesundheit und anderen Faktoren dazu neigen, mehr körperliche Schmerzen zu haben als die Allgemeinbevölkerung.

Bevor Sie überhaupt planen, die Daten zu beschaffen, eine der wichtigsten Überlegungen bei der Festlegung, wie viel Sie für Ihre KI-Trainingsdaten ausgeben sollten. In diesem Artikel geben wir Ihnen Einblicke, um ein effektives Budget für KI-Trainingsdaten zu entwickeln.

Shaip ist eine Online-Plattform, die sich auf KI-Datenlösungen im Gesundheitswesen konzentriert und lizenzierte Gesundheitsdaten anbietet, die bei der Erstellung von KI-Modellen helfen sollen. Es bietet textbasierte Patientenakten und Anspruchsdaten, Audio wie Arztaufzeichnungen oder Patienten-/Arztgespräche sowie Bilder und Videos in Form von Röntgenbildern, CT-Scans und MRT-Ergebnissen.

Daten sind eines der wichtigsten Elemente bei der Entwicklung eines KI-Algorithmus. Denken Sie daran: Nur weil Daten schneller als je zuvor generiert werden, bedeutet dies nicht, dass die richtigen Daten leicht zu finden sind. Daten von geringer Qualität, verzerrte oder falsch kommentierte Daten können (bestenfalls) einen weiteren Schritt hinzufügen. Diese zusätzlichen Schritte werden Sie ausbremsen, da die Data Science- und Entwicklungsteams diese auf dem Weg zu einer funktionsfähigen Anwendung abarbeiten müssen.

Es wurde viel über das Potenzial der künstlichen Intelligenz zur Transformation der Gesundheitsbranche gesprochen, und das aus gutem Grund. Ausgeklügelte KI-Plattformen werden von Daten angetrieben, und Gesundheitsorganisationen haben dies im Überfluss. Warum ist die Branche bei der Einführung von KI hinter anderen zurückgeblieben? Das ist eine facettenreiche Frage mit vielen möglichen Antworten. Sie alle werden jedoch zweifellos ein Hindernis besonders hervorheben: große Mengen unstrukturierter Daten.

Was jedoch einfach erscheint, ist mühsam zu entwickeln und bereitzustellen wie jedes andere komplexe KI-System. Bevor Ihr Gerät das von Ihnen aufgenommene Bild erkennen und die ML-Module (Machine Learning) es verarbeiten könnten, hätte ein Datenanmerker oder ein Team von ihnen Tausende von Stunden damit verbracht, Daten mit Anmerkungen zu versehen, um sie für Maschinen verständlich zu machen.

In diesem besonderen Gastbeitrag untersucht Vatsal Ghiya, CEO und Mitbegründer von Shaip, die drei Faktoren, von denen er glaubt, dass sie es der datengesteuerten KI in Zukunft ermöglichen werden, ihr volles Potenzial auszuschöpfen: das Talent und die Ressourcen, die für die Entwicklung innovativer Algorithmen erforderlich sind, und immense Datenmenge, um diese Algorithmen genau zu trainieren, und ausreichend Rechenleistung, um diese Daten effektiv zu analysieren. Vatsal ist ein Serial Entrepreneur mit mehr als 20 Jahren Erfahrung mit KI-Software und -Dienstleistungen im Gesundheitswesen. Shaip ermöglicht die On-Demand-Skalierung seiner Plattform, Prozesse und Mitarbeiter für Unternehmen mit den anspruchsvollsten Initiativen für maschinelles Lernen und künstliche Intelligenz.

Prozesse in Systemen der Künstlichen Intelligenz (KI) sind evolutionär. Im Gegensatz zu anderen Produkten, Dienstleistungen oder Systemen auf dem Markt bieten KI-Modelle keine sofortigen Anwendungsfälle oder sofort 100% genaue Ergebnisse. Die Ergebnisse entwickeln sich mit der weiteren Verarbeitung relevanter und qualitativ hochwertiger Daten. Es ist so, wie wenn ein Baby sprechen lernt oder wie ein Musiker damit beginnt, die ersten fünf Dur-Akkorde zu lernen und dann darauf aufzubauen. Erfolge werden nicht über Nacht freigeschaltet, aber das Training erfolgt konsequent für Spitzenleistungen.

Wenn wir über Künstliche Intelligenz (KI) und Machine Learning (ML) sprechen, stellen wir uns sofort leistungsstarke Technologieunternehmen, praktische und futuristische Lösungen, schicke selbstfahrende Autos und im Grunde alles, was ästhetisch, kreativ und intellektuell ansprechend ist, vor. Was den Menschen kaum projiziert wird, ist die reale Welt hinter all den Annehmlichkeiten und Lifestyle-Erlebnissen, die KI bietet.

Ein exklusives Interview, in dem Utsav, Business Head - Shaip mit Sunil, Executive Editor, My Startup, interagiert, um ihn darüber zu informieren, wie Shaip das menschliche Leben verbessert, indem es die Probleme der Zukunft mit seinen Angeboten für Conversational AI und Healthcare AI löst. Er erklärt weiter, wie KI und ML die Art und Weise, wie wir Geschäfte machen, revolutionieren wird und wie Shaip zur Entwicklung von Technologien der nächsten Generation beitragen wird.
Künstliche Intelligenz (KI) verbessert unseren Lebensstil durch bessere Filmempfehlungen, Restaurantvorschläge, Konfliktlösungen durch Chatbots und mehr. Die Leistungsfähigkeit, das Potenzial und die Fähigkeiten von KI werden zunehmend branchenübergreifend und in Bereichen eingesetzt, an die wahrscheinlich niemand gedacht hat. Tatsächlich wird KI in Bereichen wie Gesundheitswesen, Einzelhandel, Bankwesen, Strafjustiz, Überwachung, Einstellung, Behebung von Lohnunterschieden und mehr erforscht und implementiert.

Wir alle haben gesehen, was passiert, wenn die KI-Entwicklung schief geht. Betrachten Sie den Versuch von Amazon, ein KI-Rekrutierungssystem zu entwickeln, das eine großartige Möglichkeit war, Lebensläufe zu scannen und die qualifiziertesten Kandidaten zu identifizieren – vorausgesetzt, diese Kandidaten waren männlich.

Die Gesundheitsbranche wurde letztes Jahr aufgrund der Pandemie auf die Probe gestellt, und viele Innovationen haben sich durchgesetzt – von neuen Medikamenten und Medizinprodukten bis hin zu Durchbrüchen in der Lieferkette und besseren Zusammenarbeitsprozessen. Führungskräfte aus allen Bereichen der Branche fanden neue Wege, um das Wachstum zu beschleunigen, um das Gemeinwohl zu unterstützen und wichtige Einnahmen zu erzielen.

Wir haben sie in Filmen gesehen, in Büchern darüber gelesen und sie im wirklichen Leben erlebt. So Science-Fiction auch erscheinen mag, wir müssen uns den Tatsachen stellen – Gesichtserkennung ist hier, um zu bleiben. Die Technologie entwickelt sich dynamisch und mit den vielfältigen Anwendungsfällen, die branchenübergreifend auftauchen, scheint die breite Palette der Entwicklungen der Gesichtserkennung einfach unvermeidlich und unendlich.

Mehrsprachige Chatbots verändern die Geschäftswelt. Chatbots haben seit ihren Anfängen, in denen sie einfache Ein-Wort-Antworten lieferten, einen langen Weg zurückgelegt. Ein Chatbot kann jetzt fließend in Dutzenden von Sprachen chatten, sodass Unternehmen in einen größeren globalen Markt expandieren können.

Das Gesundheitswesen wird oft als eine Branche an der Spitze der technologischen Innovation angesehen. Das stimmt in vielerlei Hinsicht, aber der Gesundheitsbereich ist auch durch weitreichende Gesetze wie DSGVO und HIPAA sowie viele weitere lokale Richtlinien und Einschränkungen stark reguliert.

Ein Bericht aus dem Jahr 2018 ergab, dass wir jeden Tag fast 2.5 Trillionen Bytes an Daten generierten. Entgegen der landläufigen Meinung können nicht alle von uns generierten Daten zu Erkenntnissen verarbeitet werden.

Künstliche Intelligenz wird von Tag zu Tag intelligenter. Heute sind leistungsstarke Algorithmen für maschinelles Lernen in Reichweite normaler Unternehmen, und Algorithmen, die Rechenleistung erfordern, die früher massiven Mainframes vorbehalten war, können jetzt auf erschwinglichen Cloud-Servern bereitgestellt werden.