
Vorteile von OCR
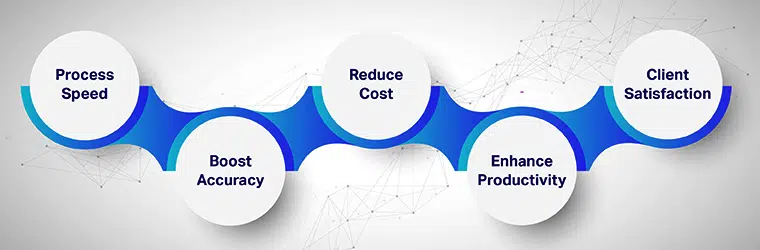
Optische Zeichenerkennung – OCR-Technologie – bringt eine Reihe von Vorteilen mit sich, von denen einige sind:
Erhöhen Sie die Geschwindigkeit des Prozesses:
Durch die schnelle Umwandlung unstrukturierter Daten in maschinenlesbare und durchsuchbare Informationen trägt die Technologie zur Beschleunigung von Geschäftsprozessen bei.
Erhöht die Genauigkeit:
Das Risiko menschlicher Fehler wird eliminiert, was die Gesamtgenauigkeit der Zeichenerkennung verbessert.
Reduziert Bearbeitungskosten:
Die Optical Character Recognition-Software ist nicht vollständig von anderen Technologien abhängig, wodurch die Verarbeitungskosten gesenkt werden.
Erhöht die Produktivität:
Da Informationen leicht verfügbar und durchsuchbar sind, haben Mitarbeiter mehr Zeit, produktive Aufgaben zu erledigen und Ziele zu erreichen.
Verbessert die Kundenzufriedenheit:
Die Verfügbarkeit von Informationen in einem leicht durchsuchbaren Format sorgt für eine höhere Zufriedenheit und ein besseres Kundenerlebnis.
Anwendungsfälle und Anwendungen
Aufbewahrung von Dokumenten / Digitalisierung von Dokumenten
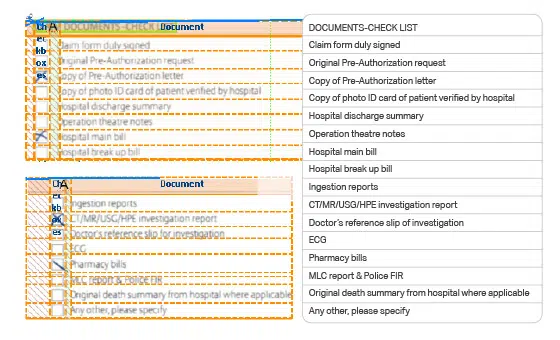 Alte historische Wertdokumente können erhalten, gespeichert und durch die Umwandlung in ein digitalisiertes Format unverwüstlich gemacht werden. Die OCR-Technologie wird zur Digitalisierung antiker und seltener Bücher verwendet, sodass diese Manuskripte mit unregelmäßigen Schriftarten digital verändert und für die Zukunft durchsuchbar gemacht werden können.
Alte historische Wertdokumente können erhalten, gespeichert und durch die Umwandlung in ein digitalisiertes Format unverwüstlich gemacht werden. Die OCR-Technologie wird zur Digitalisierung antiker und seltener Bücher verwendet, sodass diese Manuskripte mit unregelmäßigen Schriftarten digital verändert und für die Zukunft durchsuchbar gemacht werden können.
Banken und Finanzen
Der Banken- und Finanzsektor nutzt die OCT-Technologie nach Kräften. Diese Technologie trägt dazu bei, die Verhinderung von Sicherheitsbetrug zu verbessern, Risiken zu reduzieren und die Verarbeitung zu beschleunigen. Banken und Banking-Apps verwenden OCR, um wichtige Daten aus Schecks wie Kontonummer, Betrag und Handunterschrift zu extrahieren. OCR hilft bei der schnelleren Bearbeitung von Kredit- und Hypothekenanträgen, Rechnungen und Gehaltsabrechnungen.
Bevor OCR üblicher wurde, waren alle Bankdokumente wie Aufzeichnungen, Quittungen, Kontoauszüge und Schecks physisch. Mit der OCR-Digitalisierung können Banken und Finanzinstitute Prozesse rationalisieren, manuelle Fehler beseitigen und die Prozesseffizienz durch schnellen Datenzugriff verbessern.
Kennzeichenerkennung
 Die OCR-Technologie wird häufig zur Identifizierung von Nummern und Text auf Nummernschildern verwendet. Diese Technologie wird verwendet, um verlorene Autos zu identifizieren, Parkgebühren zu berechnen und Fahrzeugkriminalität zu verhindern.
Die OCR-Technologie wird häufig zur Identifizierung von Nummern und Text auf Nummernschildern verwendet. Diese Technologie wird verwendet, um verlorene Autos zu identifizieren, Parkgebühren zu berechnen und Fahrzeugkriminalität zu verhindern.
Die OCR-Technologie hilft bei der Umsetzung von Verkehrssicherheitsregeln, um Betrug und Verbrechen zu vermeiden. Da die Nummernschilder eines Fahrzeugs mit den Ausweisen des Fahrers verknüpft sind, ist die Identifizierung einfacher.
Darüber hinaus bestehen die Nummernschilder aus einer gut geschriebenen Reihe von Zahlen und Texten, die für das KI-Modell nicht schwer zu lesen sind, was es einfacher und genauer macht.
Text-to-Speech
Die Text-to-Speech-Anwendung der OCR-Technologie ist eine hervorragende Hilfe für sehbehinderte Menschen, um leichter zu funktionieren. Die OCR-Technologie hilft beim Scannen physischer und digitaler Texte und bei der Verwendung von Sprachgeräten. Anschließend wird der Inhalt laut vorgelesen. Obwohl der Text-zu-Sprache-Aspekt der OCR-Technologie eine der ersten Anwendungen war, wird sie jetzt weiterentwickelt und verbessert, um den einzigartigen Bedürfnissen von Menschen mit Sehbehinderung gerecht zu werden, indem mehrere Dialekte und Sprachen unterstützt werden.
Transkription von Multi-Kategorie Gescannte Papierdokumente Datensätze
 Mithilfe der OCR-Technologie werden auch Rechnungen, Quittungen, Rechnungen und andere Dokumente unterschiedlicher Kategorien effektiv transkribiert. Newsletter, Papiere mit Zahlen in Kreisen, Checkbox-Formulare und Dokumente mit mehreren Kategorien wie Steuerformulare und Handbücher können ebenfalls digitalisiert werden.
Mithilfe der OCR-Technologie werden auch Rechnungen, Quittungen, Rechnungen und andere Dokumente unterschiedlicher Kategorien effektiv transkribiert. Newsletter, Papiere mit Zahlen in Kreisen, Checkbox-Formulare und Dokumente mit mehreren Kategorien wie Steuerformulare und Handbücher können ebenfalls digitalisiert werden.
Transkribieren Sie medizinische Etiketten mit OCR
 Durch die Unterstützung beim Scannen von verschreibungspflichtigen medizinischen Etiketten mit OCR ist es jetzt möglich, medizinische Daten automatisch zu erfassen. Das medizinische Daten erfasst werden von handschriftlichen Rezepten, Medikamenteninformationen und Menge, um manuelle Fehler, Doppelarbeit und Nachlässigkeit zu vermeiden.
Durch die Unterstützung beim Scannen von verschreibungspflichtigen medizinischen Etiketten mit OCR ist es jetzt möglich, medizinische Daten automatisch zu erfassen. Das medizinische Daten erfasst werden von handschriftlichen Rezepten, Medikamenteninformationen und Menge, um manuelle Fehler, Doppelarbeit und Nachlässigkeit zu vermeiden.
Mit OCR kann die Gesundheitsbranche die Krankengeschichte eines Patienten schnell scannen, speichern und suchen. Die OCR ermöglicht die Digitalisierung und Speicherung von Scanberichten, Behandlungshistorien, Krankenhausunterlagen, Versicherungsunterlagen, Röntgenbildern und anderen Dokumenten. Durch Digitalisierung, Transkription und Speicherung medizinischer Etiketten erleichtert OCR die Rationalisierung des Prozessablaufs und beschleunigt die Gesundheitsversorgung.
Erkennen von Straße/Straße und Extrahieren von Informationen Straßentafeldaten mit OCR
 Die automatische Erkennung, Identifizierung und Klassifizierung von Straßen-/Straßenschildern erfolgt mit OCR. Durch die Erkennung von Verkehrszeichen weist OCR die Fahrer auf eine sicherere Fahrt hin. Die OCR-Technologie funktioniert auch bei schlechten Lichtverhältnissen, erkennt Verkehrszeichen in mehreren Sprachen und unterschiedlich geformte Schilder und klassifiziert diese für die Zukunft.
Die automatische Erkennung, Identifizierung und Klassifizierung von Straßen-/Straßenschildern erfolgt mit OCR. Durch die Erkennung von Verkehrszeichen weist OCR die Fahrer auf eine sicherere Fahrt hin. Die OCR-Technologie funktioniert auch bei schlechten Lichtverhältnissen, erkennt Verkehrszeichen in mehreren Sprachen und unterschiedlich geformte Schilder und klassifiziert diese für die Zukunft.
Um eine zu entwickeln intelligente Zeichenerkennung Tool müssen Sie es mit dem projektspezifischen Datensatz trainieren.
Bei Shaip stellen wir einen vollständig angepassten Dokumentendatensatz zur Verfügung, um ihn hochfunktional zu entwickeln OCR für AI- und ML-Modelle. Unser spezialisiertes Prozess der OCR hilft bei der Entwicklung optimierter Lösungen für Kunden.
Wir bieten umfangreiche und zuverlässige Datensätze, die Tausende verschiedener extrahierter Daten aus gescannten Dokumenten enthalten. Nehmen Sie Kontakt mit unserem auf OCR-Lösungen Experten erfahren, wie wir skalierbare, erschwingliche und kundenspezifische Datensätze bereitstellen.


