
Künstliche Intelligenz revolutioniert die Musikindustrie und bietet automatisierte Kompositions-, Mastering- und Performance-Tools. KI-Algorithmen generieren neuartige Kompositionen, sagen Hits voraus und personalisieren das Hörerlebnis und verändern so die Musikproduktion, den Vertrieb und den Konsum. Diese neue Technologie bietet sowohl spannende Möglichkeiten als auch herausfordernde ethische Dilemmata.
Modelle für maschinelles Lernen (ML) erfordern Trainingsdaten, um effektiv zu funktionieren, so wie ein Komponist Noten benötigt, um eine Symphonie zu schreiben. In der Musikwelt, in der Melodie, Rhythmus und Emotionen ineinandergreifen, kann die Bedeutung hochwertiger Trainingsdaten nicht genug betont werden. Es ist das Rückgrat der Entwicklung robuster und genauer Musik-ML-Modelle für prädiktive Analysen, Genreklassifizierung oder automatische Transkription.
Daten, das Lebenselixier von ML-Modellen
Maschinelles Lernen ist von Natur aus datengesteuert. Diese Rechenmodelle lernen Muster aus den Daten und können so Vorhersagen oder Entscheidungen treffen. Bei Musik-ML-Modellen liegen die Trainingsdaten häufig in Form digitalisierter Musiktitel, Liedtexte, Metadaten oder einer Kombination dieser Elemente vor. Die Qualität, Quantität und Vielfalt dieser Daten hat erheblichen Einfluss auf die Wirksamkeit des Modells.

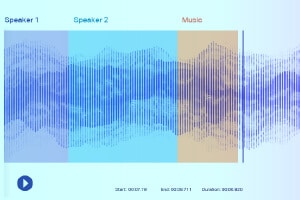
Sound-Beschriftung
Beim Sound-Labeling erhalten die Datenannotatoren eine Aufnahme und müssen alle benötigten Sounds separieren und kennzeichnen. Dabei kann es sich beispielsweise um bestimmte Schlüsselwörter oder den Klang eines bestimmten Musikinstruments handeln.

Musikklassifikation
Datenannotatoren können in dieser Art von Audioanmerkungen Genres oder Instrumente markieren. Die Musikklassifizierung ist sehr nützlich, um Musikbibliotheken zu organisieren und Benutzerempfehlungen zu verbessern.

Segmentierung auf phonetischer Ebene
Beschriftung und Klassifizierung phonetischer Segmente in den Wellenformen und Spektrogrammen von Aufnahmen von Personen, die Acapella singen.
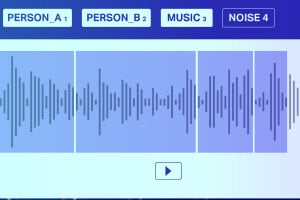
Klangklassifizierung
Abgesehen von Stille/weißem Rauschen besteht eine Audiodatei typischerweise aus den folgenden Geräuschtypen: Sprache, Geplapper, Musik und Rauschen. Kommentieren Sie Musiknoten präzise, um eine höhere Genauigkeit zu erzielen.
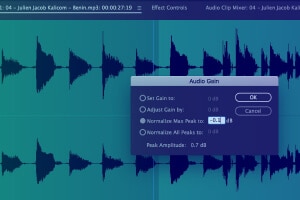
Erfassung von Metadateninformationen
Erfassen Sie wichtige Informationen wie Startzeit, Endzeit, Segment-ID, Lautstärkepegel, primäre Tonart, Sprachcode, Sprecher-ID und andere Transkriptionskonventionen usw.


