
Eine robuste KI-basierte Lösung basiert auf Daten – nicht irgendwelchen Daten, sondern qualitativ hochwertigen, genau kommentierten Daten. Nur die besten und raffiniertesten Daten können Ihr KI-Projekt vorantreiben, und diese Datenreinheit wird einen enormen Einfluss auf das Ergebnis des Projekts haben.
Wir haben Daten oft als Treibstoff für KI-Projekte bezeichnet, aber nicht irgendwelche Daten reichen aus. Wenn Sie Raketentreibstoff benötigen, um Ihrem Projekt beim Abheben zu helfen, können Sie kein Rohöl in den Tank füllen. Stattdessen müssen Daten (wie Kraftstoff) sorgfältig verfeinert werden, um sicherzustellen, dass nur die qualitativ hochwertigsten Informationen Ihr Projekt vorantreiben. Dieser Verfeinerungsprozess wird als Datenannotation bezeichnet, und es gibt einige hartnäckige Missverständnisse darüber.
Definieren Sie die Trainingsdatenqualität in Annotation
Wir wissen, dass die Datenqualität einen großen Einfluss auf das Ergebnis des KI-Projekts hat. Einige der besten und leistungsstärksten ML-Modelle basieren auf detaillierten und genau gekennzeichneten Datensätzen.
Aber wie genau definieren wir Qualität in einer Anmerkung?
Wenn wir darüber reden Datenanmerkung Qualität, Genauigkeit, Zuverlässigkeit und Konsistenz sind wichtig. Ein Datensatz gilt als genau, wenn er mit der Grundwahrheit und den Informationen aus der realen Welt übereinstimmt.
Datenkonsistenz bezieht sich auf den Genauigkeitsgrad, der im gesamten Datensatz beibehalten wird. Die Qualität eines Datensatzes wird jedoch genauer durch die Art des Projekts, seine einzigartigen Anforderungen und das gewünschte Ergebnis bestimmt. Daher sollte dies das Kriterium für die Bestimmung der Datenkennzeichnung und der Annotationsqualität sein.
Warum ist es wichtig, die Datenqualität zu definieren?
Es ist wichtig, die Datenqualität zu definieren, da sie als umfassender Faktor fungiert, der die Qualität des Projekts und des Ergebnisses bestimmt.
- Daten von schlechter Qualität können sich auf die Produkt- und Geschäftsstrategien auswirken.
- Ein maschinelles Lernsystem ist nur so gut wie die Qualität der Daten, mit denen es trainiert wird.
- Gute Datenqualität eliminiert Nacharbeiten und damit verbundene Kosten.
- Es hilft Unternehmen, fundierte Projektentscheidungen zu treffen und die Einhaltung gesetzlicher Vorschriften einzuhalten.
Wie messen wir die Qualität der Trainingsdaten beim Labeln?

Es gibt mehrere Methoden, um die Qualität von Trainingsdaten zu messen, und die meisten beginnen damit, zunächst eine konkrete Richtlinie zur Datenannotation zu erstellen. Einige der Methoden umfassen:
Von Experten erstellte Benchmarks
Qualitätsmaßstäbe bzw Goldstandard-Anmerkung Methoden sind die einfachsten und kostengünstigsten Qualitätssicherungsoptionen, die als Bezugspunkt dienen, um die Qualität des Projektergebnisses zu messen. Es misst die Datenannotationen an dem von den Experten festgelegten Benchmark.
Cronbachs Alpha-Test
Cronbachs Alpha-Test bestimmt die Korrelation oder Konsistenz zwischen Datensätzen. Die Zuverlässigkeit des Labels und größere Genauigkeit kann auf der Grundlage der Forschung gemessen werden.
Konsensmessung
Die Konsensmessung bestimmt den Grad der Übereinstimmung zwischen maschinellen oder menschlichen Kommentatoren. In der Regel sollte für jeden Punkt ein Konsens erzielt und bei Meinungsverschiedenheiten geschlichtet werden.
Panel-Überprüfung
Ein Expertengremium bestimmt normalerweise die Genauigkeit des Etiketts, indem es die Datenetiketten überprüft. Manchmal wird normalerweise ein definierter Teil von Datenetiketten als Stichprobe zur Bestimmung der Genauigkeit genommen.
Reviewing Trainingsdaten Qualität
Die Unternehmen, die KI-Projekte übernehmen, sind voll und ganz von der Kraft der Automatisierung überzeugt, weshalb viele weiterhin der Meinung sind, dass die automatische Annotation durch KI schneller und genauer ist als die manuelle Annotation. Momentan ist die Realität so, dass es Menschen braucht, um Daten zu identifizieren und zu klassifizieren, weil Genauigkeit so wichtig ist. Die durch die automatische Kennzeichnung verursachten zusätzlichen Fehler erfordern zusätzliche Iterationen, um die Genauigkeit des Algorithmus zu verbessern, wodurch jegliche Zeitersparnis zunichte gemacht wird.
Ein weiteres Missverständnis – und eines, das wahrscheinlich zur Einführung der automatischen Annotation beiträgt – ist, dass kleine Fehler keine großen Auswirkungen auf die Ergebnisse haben. Selbst kleinste Fehler können aufgrund eines Phänomens namens KI-Drift zu erheblichen Ungenauigkeiten führen, bei dem Inkonsistenzen in den Eingabedaten einen Algorithmus in eine Richtung führen, die Programmierer nie beabsichtigt hatten.
Die Qualität der Trainingsdaten – die Aspekte Genauigkeit und Konsistenz – werden ständig überprüft, um den einzigartigen Anforderungen der Projekte gerecht zu werden. Eine Überprüfung der Trainingsdaten wird typischerweise mit zwei verschiedenen Methoden durchgeführt –
Automatisch kommentierte Techniken
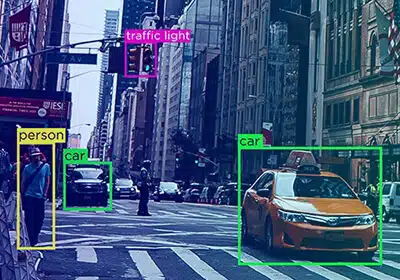 Der automatische Überprüfungsprozess für Anmerkungen stellt sicher, dass Feedback in das System zurückgeleitet wird, und verhindert Fehlschlüsse, sodass Kommentatoren ihre Prozesse verbessern können.
Der automatische Überprüfungsprozess für Anmerkungen stellt sicher, dass Feedback in das System zurückgeleitet wird, und verhindert Fehlschlüsse, sodass Kommentatoren ihre Prozesse verbessern können.
Automatische Anmerkungen, die von künstlicher Intelligenz gesteuert werden, sind genau und schneller. Die automatische Annotation reduziert die Zeit, die manuelle QAs für die Überprüfung aufwenden, sodass sie mehr Zeit für komplexe und kritische Fehler im Datensatz aufwenden können. Automatische Anmerkungen können auch dabei helfen, ungültige Antworten, Wiederholungen und falsche Anmerkungen zu erkennen.
Manuell über Data-Science-Experten
Data Scientists überprüfen auch die Datenannotation, um die Genauigkeit und Zuverlässigkeit des Datensatzes sicherzustellen.
Kleine Fehler und Ungenauigkeiten in den Anmerkungen können das Ergebnis des Projekts erheblich beeinflussen. Und diese Fehler werden möglicherweise nicht von den Überprüfungstools für automatische Anmerkungen erkannt. Data Scientists führen Stichprobenqualitätstests mit unterschiedlichen Chargengrößen durch, um Dateninkonsistenzen und unbeabsichtigte Fehler im Datensatz zu erkennen.
Hinter jeder KI-Schlagzeile steckt ein Annotationsprozess, und Shaip kann helfen, ihn schmerzfrei zu machen Pa
Fallstricke bei KI-Projekten vermeiden
Viele Organisationen leiden unter einem Mangel an internen Anmerkungsressourcen. Data Scientists und Ingenieure sind sehr gefragt, und die Einstellung einer ausreichenden Zahl dieser Fachleute für ein KI-Projekt bedeutet, einen Scheck zu schreiben, der für die meisten Unternehmen unerschwinglich ist. Anstatt sich für eine Budgetoption zu entscheiden (z. B. Crowdsourcing-Anmerkung), die Sie schließlich heimsuchen wird, sollten Sie Ihre Anmerkungsanforderungen an einen erfahrenen externen Partner auslagern. Das Outsourcing gewährleistet ein hohes Maß an Genauigkeit und reduziert gleichzeitig die Engpässe bei der Einstellung, Schulung und Verwaltung, die entstehen, wenn Sie versuchen, ein internes Team zusammenzustellen.
Wenn Sie Ihre Annotationsanforderungen speziell an Shaip auslagern, greifen Sie auf eine starke Kraft zurück, die Ihre KI-Initiative beschleunigen kann, ohne die Abkürzungen, die alle wichtigen Ergebnisse beeinträchtigen. Wir bieten eine vollständig verwaltete Belegschaft, was bedeutet, dass Sie eine weitaus größere Genauigkeit erzielen können, als Sie dies durch Crowdsourcing-Annotationsbemühungen erreichen würden. Die Vorabinvestition ist zwar höher, zahlt sich jedoch während des Entwicklungsprozesses aus, wenn weniger Iterationen erforderlich sind, um das gewünschte Ergebnis zu erzielen.
Unsere Datenservices decken auch den gesamten Prozess ab, einschließlich der Beschaffung, eine Fähigkeit, die die meisten anderen Etikettierungsanbieter nicht bieten können. Mit unserer Erfahrung können Sie schnell und einfach große Mengen qualitativ hochwertiger, geografisch unterschiedlicher Daten erfassen, die anonymisiert wurden und allen relevanten Vorschriften entsprechen. Wenn Sie diese Daten in unserer Cloud-basierten Plattform speichern, erhalten Sie auch Zugriff auf bewährte Tools und Workflows, die die Gesamteffizienz Ihres Projekts steigern und Ihnen helfen, schneller voranzukommen, als Sie es für möglich gehalten hätten.
Und schließlich unsere interne Branchenexperten verstehen Sie Ihre individuellen Bedürfnisse. Egal, ob Sie einen Chatbot bauen oder an der Anwendung von Gesichtserkennungstechnologie arbeiten, um die Gesundheitsversorgung zu verbessern, wir waren da und können Ihnen helfen, Richtlinien zu entwickeln, die sicherstellen, dass der Annotationsprozess die für Ihr Projekt skizzierten Ziele erreicht.
Wir bei Shaip freuen uns nicht nur auf die neue Ära der KI. Wir helfen dabei auf unglaubliche Weise und unsere Erfahrung hat uns geholfen, unzählige erfolgreiche Projekte auf den Weg zu bringen. Um zu sehen, was wir für Ihre eigene Implementierung tun können, wenden Sie sich an uns DEMOVERSION ANFORDERN heute.


