



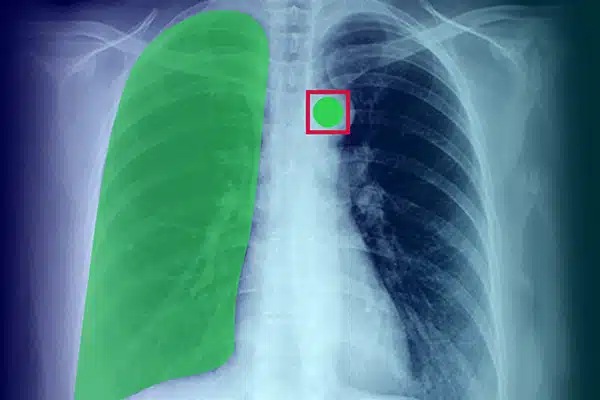
Bildanmerkung
Verbessern Sie die medizinische KI, indem Sie visuelle Daten aus Röntgenaufnahmen, CT-Scans und MRTs mit Anmerkungen versehen. Stellen Sie sicher, dass KI-Modelle bei der Diagnose und Behandlung eine hervorragende Leistung erbringen, unterstützt durch fachkundige Datenkennzeichnung. Erzielen Sie bessere Patientenergebnisse mit überlegenen Bildgebungserkenntnissen.
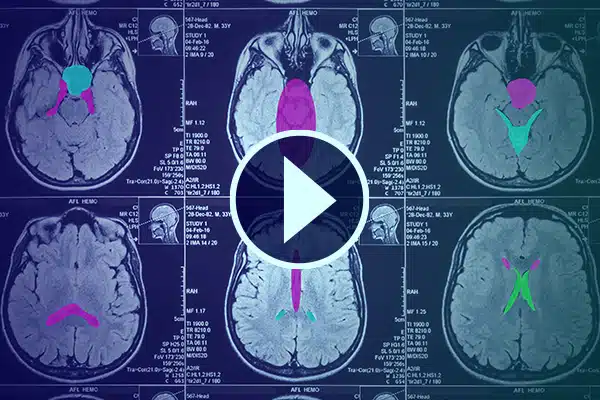
Videoanmerkung
Fördern Sie die KI im Gesundheitswesen mit detaillierter Videoanmerkung. Verbessern Sie das KI-Lernen mit Klassifizierungen und Segmentierungen in medizinischem Filmmaterial. Verbessern Sie Ihre chirurgische KI und Patientenüberwachung für eine bessere Gesundheitsversorgung und Diagnose.
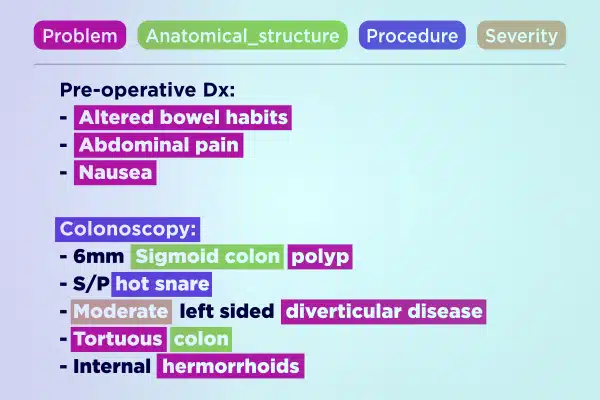
Textanmerkung
Optimieren Sie die medizinische KI-Entwicklung mit fachmännisch kommentierten Textdaten. Analysieren und bereichern Sie schnell große Textmengen, von handschriftlichen Notizen bis hin zu Versicherungsberichten. Stellen Sie genaue und umsetzbare Erkenntnisse für Fortschritte im Gesundheitswesen sicher.

Audiokommentar
Nutzen Sie NLP-Expertise, um medizinische Audiodaten präzise zu kommentieren und zu kennzeichnen. Erstellen Sie sprachgestützte Systeme für nahtlose klinische Abläufe und integrieren Sie KI in verschiedene sprachaktivierte Gesundheitsprodukte. Verbessern Sie die diagnostische Präzision mit der fachmännischen Audiodatenkuration.

Medizinische Kodierung
Optimieren Sie die medizinische Dokumentation, indem Sie sie mithilfe der medizinischen KI-Kodierung in universelle Codes umwandeln. Sorgen Sie für Genauigkeit, verbessern Sie die Abrechnungseffizienz und unterstützen Sie eine nahtlose Bereitstellung von Gesundheitsdienstleistungen mit modernster KI-Unterstützung bei der Codierung von Krankenakten.

Phase 1: Technisches Fachwissen (Umfang und Anmerkungsrichtlinien verstehen)

Phase 2: Schulung geeigneter Ressourcen für das Projekt

Phase 3: Feedback-Zyklus und QS der kommentierten Dokumente
Radiologie
Unser Bildanmerkungsdienst für die Radiologie schärft die KI-Diagnose und bietet eine zusätzliche Ebene an Fachwissen. Jeder Röntgen-, MRT- und CT-Scan wird sorgfältig beschriftet und von einem Fachexperten überprüft. Dieser zusätzliche Schritt beim Training und bei der Überprüfung steigert die Fähigkeit der KI, Anomalien und Krankheiten zu erkennen. Es erhöht die Genauigkeit vor der Auslieferung an unsere Kunden.

Kardiologie
Unsere auf die Kardiologie ausgerichtete Bildannotation schärft die KI-Diagnostik. Wir ziehen Kardiologieexperten hinzu, die komplexe herzbezogene Bilder beschriften und unsere KI-Modelle trainieren. Bevor wir Daten an Kunden senden, überprüfen diese Spezialisten jedes Bild, um höchste Genauigkeit sicherzustellen. Dieser Prozess ermöglicht es der KI, Herzerkrankungen genauer zu erkennen.
Zahnheilkunde
Unser Bildanmerkungsservice in der Zahnmedizin beschriftet Zahnbilder, um KI-Diagnosetools zu verbessern. Durch die genaue Erkennung von Karies, Ausrichtungsproblemen und anderen Zahnerkrankungen ermöglichen unsere KMU der KI, die Patientenergebnisse zu verbessern und Zahnärzte bei der präzisen Behandlungsplanung und Früherkennung zu unterstützen.


















Personen
Engagierte und geschulte Teams:
- 30,000+ Mitarbeiter für Datenerstellung, Kennzeichnung und QA
- Zertifiziertes Projektmanagement-Team
- Erfahrenes Produktentwicklungsteam
- Talentpool-Sourcing- und Onboarding-Team

Prozess
Höchste Prozesseffizienz wird gewährleistet durch:
- Robuster 6-Sigma-Stage-Gate-Prozess
- Ein engagiertes Team von 6 Sigma Black Belts – Key Process Owners & Quality Compliance
- Kontinuierliche Verbesserung und Feedbackschleife

Plattform
Die patentierte Plattform bietet Vorteile:
- Webbasierte End-to-End-Plattform
- Einwandfreie Qualität
- Schnellere TAT
- Nahtlose Lieferung



