
Der Schlüssel zur Überwindung von Hindernissen bei der KI-Entwicklung: Zuverlässigere Daten
Heute hat der Durchschnittsmensch millionenfach mehr Rechenleistung in der Tasche, als die NASA 1969 bei der Mondlandung durchziehen musste. Das gleiche allgegenwärtige Gerät, das praktischerweise eine Fülle an Rechenleistung demonstriert, erfüllt auch eine weitere Voraussetzung für das goldene Zeitalter der KI: eine Fülle von Daten. Nach Erkenntnissen der Information Overload Research Group wurden 90 % der weltweiten Daten in den letzten zwei Jahren erstellt. Nachdem sich das exponentielle Wachstum der Rechenleistung nun endlich mit einem ebenso rasanten Wachstum der Datengenerierung konvergiert hat, explodieren die KI-Dateninnovationen so stark, dass einige Experten glauben, dass sie eine vierte industrielle Revolution in Gang setzen werden.
Daten der National Venture Capital Association zeigen, dass der KI-Sektor im ersten Quartal 6.9 Rekordinvestitionen in Höhe von 2020 Milliarden US-Dollar verzeichnete. Es ist nicht schwer, das Potenzial von KI-Tools zu erkennen, da es bereits überall um uns herum erschlossen wird. Einige der sichtbareren Anwendungsfälle für KI-Produkte sind die Empfehlungsmaschinen hinter unseren Lieblingsanwendungen wie Spotify und Netflix. Obwohl es Spaß macht, einen neuen Künstler zum Anhören oder eine neue TV-Show zum Binge-Watching zu entdecken, sind diese Implementierungen eher gering. Andere Algorithmen bewerten Testergebnisse – zum Teil bestimmen sie, wo Studenten ins College aufgenommen werden – und wieder andere durchsuchen die Lebensläufe der Kandidaten und entscheiden, welche Bewerber einen bestimmten Job bekommen. Einige KI-Tools können sogar Auswirkungen auf Leben oder Tod haben, wie zum Beispiel das KI-Modell, das auf Brustkrebs untersucht (das Ärzte übertrifft).
Trotz des stetigen Wachstums sowohl bei den realen Beispielen der KI-Entwicklung als auch bei der Zahl der Startups, die um die Entwicklung der nächsten Generation von Transformationstools kämpfen, bleiben die Herausforderungen für eine effektive Entwicklung und Implementierung bestehen. Insbesondere ist die KI-Ausgabe nur so genau, wie es die Eingabe zulässt, was bedeutet, dass Qualität von größter Bedeutung ist.

Umgang mit komplexen Compliance-Anforderungen
Als ob es nicht schon schwierig genug wäre, qualitativ hochwertige Daten zu finden, sind einige der Branchen, die am meisten von KI-Dateninnovationen profitieren, auch die am stärksten regulierten. Das Gesundheitswesen ist vielleicht das beste Beispiel, und während eine Umfrage von HIT Infrastructure ergab, dass 91 % der Brancheninsider glauben, dass die Technologie den Zugang zur Gesundheitsversorgung verbessern könnte, wird der Optimismus durch die Tatsache gedämpft, dass 75 % sie als Bedrohung für die Patientensicherheit und den Datenschutz sehen — und Patienten sind nicht die einzigen gefährdeten Personen.
Die weitreichenden Vorschriften, die durch den Health Insurance Portability and Accountability Act erlassen wurden, überschneiden sich nun mit verschiedenen lokalen Hürden bei der Einhaltung von Daten, wie der europäischen Datenschutz-Grundverordnung, dem California Consumer Privacy Act in den Vereinigten Staaten und dem Personal Data Protection Act in Singapur. Zu diesen lokalen Vorschriften werden noch viele weitere hinzukommen, und da die Telemedizin zu einer wichtigeren Quelle für Gesundheitsdaten wird, ist es wahrscheinlich, dass die Vorschriften die Patientendaten beim Transport noch stärker in den Griff bekommen. Infolgedessen wird sich die sichere und konforme Cloud-Plattform von Shaip als noch wertvolleres Mittel erweisen, Gesundheitsdaten zu sammeln und darauf zuzugreifen, um KI-Produkte zu trainieren.
Persönlich identifizierbare Informationen können eine erhebliche Bedrohung für Ihre KI-Entwicklung darstellen, aber selbst eine vollständig konforme Implementierung ist gefährdet, wenn sie keine genauen Ergebnisse liefern kann, die nur mit unterschiedlichen Trainingsdaten erzielt werden. Eine Studie aus dem Jahr 2020 im Journal of the American Medical Association zeigte, dass maschinelle Lernalgorithmen im medizinischen Bereich am häufigsten mit Daten von Patienten in Kalifornien, New York und Massachusetts trainiert werden. Angesichts der Tatsache, dass diese Patienten weniger als ein Fünftel der US-Bevölkerung ausmachen, ganz zu schweigen vom Rest der Welt, ist es schwer vorstellbar, wie diese Modelle zu etwas anderem als voreingenommenen Ergebnissen führen könnten.

 In Anbetracht der Schwierigkeit, konforme, geografisch vielfältige Informationen zu sichern, bietet Shaip lizenzierte Gesundheitsdaten aus einer Vielzahl von Regionen an, die speziell mit dem Ziel kuratiert wurden, genaue Algorithmen zu entwickeln. Diese Daten liegen in Form von Text vor, z. B. Krankenakten oder Anspruchsinformationen, medizinisch-diagnostischer Bildgebung wie CT-Scans, Audio wie gesprochenen Notizen von Ärzten oder Gesprächen zwischen Ärzten und Patienten und sogar Video von MRT-Ergebnissen. Es ist außerdem vollständig anonymisiert und schützt Ihr Unternehmen sowohl vor ethischen als auch vor finanziellen Folgen, die durch einen Verstoß gegen die zunehmende Zahl von Vorschriften für Daten nationaler und internationaler Herkunft entstehen können.
In Anbetracht der Schwierigkeit, konforme, geografisch vielfältige Informationen zu sichern, bietet Shaip lizenzierte Gesundheitsdaten aus einer Vielzahl von Regionen an, die speziell mit dem Ziel kuratiert wurden, genaue Algorithmen zu entwickeln. Diese Daten liegen in Form von Text vor, z. B. Krankenakten oder Anspruchsinformationen, medizinisch-diagnostischer Bildgebung wie CT-Scans, Audio wie gesprochenen Notizen von Ärzten oder Gesprächen zwischen Ärzten und Patienten und sogar Video von MRT-Ergebnissen. Es ist außerdem vollständig anonymisiert und schützt Ihr Unternehmen sowohl vor ethischen als auch vor finanziellen Folgen, die durch einen Verstoß gegen die zunehmende Zahl von Vorschriften für Daten nationaler und internationaler Herkunft entstehen können.
Hindernisse bei der KI-Entwicklung überwinden
Die KI-Entwicklungsbemühungen beinhalten erhebliche Hindernisse, unabhängig davon, in welcher Branche sie tätig sind, und der Weg von einer umsetzbaren Idee zu einem erfolgreichen Produkt ist mit Schwierigkeiten verbunden. Zwischen den Herausforderungen, die richtigen Daten zu beschaffen, und der Notwendigkeit, sie zu anonymisieren, um alle relevanten Vorschriften einzuhalten, kann es sich anfühlen, als wäre die eigentliche Konstruktion und das Training eines Algorithmus der einfache Teil.
Um Ihrem Unternehmen alle Vorteile zu bieten, die bei der Entwicklung einer bahnbrechenden neuen KI-Entwicklung erforderlich sind, sollten Sie eine Partnerschaft mit einem Unternehmen wie Shaip in Betracht ziehen. Chetan Parikh und Vatsal Ghiya gründeten Shaip, um Unternehmen bei der Entwicklung von Lösungen zu unterstützen, die das Gesundheitswesen in den USA verändern könnten. Nach mehr als 16 Jahren im Geschäft ist unser Unternehmen auf mehr als 600 Teammitglieder angewachsen und wir haben mit Hunderten von Mitarbeitern zusammengearbeitet Kunden, um überzeugende Ideen in KI-Lösungen zu verwandeln.
Wenn unsere Mitarbeiter, Prozesse und Plattformen für Ihr Unternehmen arbeiten, können Sie sofort die folgenden vier Vorteile nutzen und Ihr Projekt zu einem erfolgreichen Abschluss katapultieren:
1. Die Fähigkeit, Ihre Datenwissenschaftler zu befreien
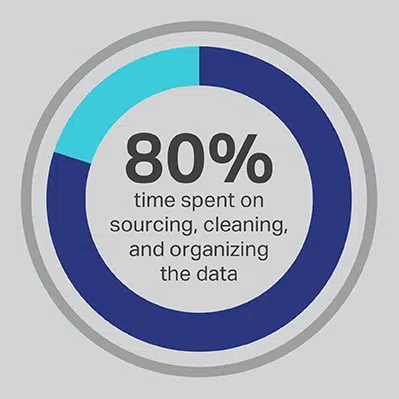
Es führt kein Weg daran vorbei, dass der KI-Entwicklungsprozess viel Zeit in Anspruch nimmt, aber Sie können immer die Funktionen optimieren, die Ihr Team am meisten aufwendet. Sie haben Ihre Datenwissenschaftler eingestellt, weil sie Experten in der Entwicklung fortschrittlicher Algorithmen und Modelle für maschinelles Lernen sind, aber die Forschung zeigt immer wieder, dass diese Mitarbeiter tatsächlich 80 % ihrer Zeit damit verbringen, die Daten zu beschaffen, zu bereinigen und zu organisieren, die das Projekt antreiben. Mehr als drei Viertel (76 %) der Datenwissenschaftler geben an, dass diese alltäglichen Datenerfassungsprozesse zufällig auch ihre am wenigsten bevorzugten Teile ihrer Arbeit sind, aber der Bedarf an hochwertigen Daten lässt nur 20 % ihrer Zeit für die eigentliche Entwicklung übrig die interessanteste und intellektuell anregendste Arbeit für viele Datenwissenschaftler. Durch die Beschaffung von Daten über einen Drittanbieter wie Shaip kann ein Unternehmen seine teuren und talentierten Dateningenieure ihre Arbeit als Datenpfleger auslagern lassen und stattdessen ihre Zeit mit den Teilen von KI-Lösungen verbringen, in denen sie den größten Nutzen erzielen können.
2. Die Fähigkeit, bessere Ergebnisse zu erzielen
 Viele Führungskräfte in der KI-Entwicklung entscheiden sich, Open-Source- oder Crowdsourcing-Daten zu verwenden, um die Kosten zu senken, aber diese Entscheidung kostet auf lange Sicht fast immer mehr. Diese Datentypen sind leicht verfügbar, können jedoch nicht mit der Qualität sorgfältig kuratierter Datensätze mithalten. Insbesondere Crowdsourcing-Daten sind voller Fehler, Auslassungen und Ungenauigkeiten, und obwohl diese Probleme manchmal während des Entwicklungsprozesses unter den wachsamen Augen Ihrer Ingenieure behoben werden können, sind zusätzliche Iterationen erforderlich, die nicht erforderlich wären, wenn Sie mit höheren Werten beginnen -Qualitätsdaten von Anfang an.
Viele Führungskräfte in der KI-Entwicklung entscheiden sich, Open-Source- oder Crowdsourcing-Daten zu verwenden, um die Kosten zu senken, aber diese Entscheidung kostet auf lange Sicht fast immer mehr. Diese Datentypen sind leicht verfügbar, können jedoch nicht mit der Qualität sorgfältig kuratierter Datensätze mithalten. Insbesondere Crowdsourcing-Daten sind voller Fehler, Auslassungen und Ungenauigkeiten, und obwohl diese Probleme manchmal während des Entwicklungsprozesses unter den wachsamen Augen Ihrer Ingenieure behoben werden können, sind zusätzliche Iterationen erforderlich, die nicht erforderlich wären, wenn Sie mit höheren Werten beginnen -Qualitätsdaten von Anfang an.
Das Vertrauen auf Open-Source-Daten ist eine weitere häufige Abkürzung, die mit ihren eigenen Fallstricken verbunden ist. Mangelnde Differenzierung ist eines der größten Probleme, da ein mit Open-Source-Daten trainierter Algorithmus leichter repliziert werden kann als einer, der auf lizenzierten Datensätzen basiert. Wenn Sie diesen Weg gehen, laden Sie die Konkurrenz von anderen Marktteilnehmern ein, die Ihre Preise unterbieten und jederzeit Marktanteile gewinnen könnten. Wenn Sie sich auf Shaip verlassen, greifen Sie auf die hochwertigsten Daten zu, die von einer geschickten, verwalteten Belegschaft zusammengestellt wurden, und wir können Ihnen eine exklusive Lizenz für einen benutzerdefinierten Datensatz erteilen, der verhindert, dass Konkurrenten Ihr hart erkämpftes geistiges Eigentum einfach neu erstellen können.
3. Zugang zu erfahrenen Fachleuten
 Auch wenn Ihr interner Dienstplan qualifizierte Ingenieure und talentierte Datenwissenschaftler umfasst, können Ihre KI-Tools von der Weisheit profitieren, die nur durch Erfahrung entsteht. Unsere Fachexperten haben zahlreiche KI-Implementierungen in ihren Bereichen angeführt und dabei wertvolle Lektionen gelernt. Ihr einziges Ziel ist es, Ihnen zu helfen, Ihre Ziele zu erreichen.
Auch wenn Ihr interner Dienstplan qualifizierte Ingenieure und talentierte Datenwissenschaftler umfasst, können Ihre KI-Tools von der Weisheit profitieren, die nur durch Erfahrung entsteht. Unsere Fachexperten haben zahlreiche KI-Implementierungen in ihren Bereichen angeführt und dabei wertvolle Lektionen gelernt. Ihr einziges Ziel ist es, Ihnen zu helfen, Ihre Ziele zu erreichen.
Da Domänenexperten Daten für Sie identifizieren, organisieren, kategorisieren und kennzeichnen, wissen Sie, dass die zum Trainieren Ihres Algorithmus verwendeten Informationen die bestmöglichen Ergebnisse erzielen können. Außerdem führen wir eine regelmäßige Qualitätssicherung durch, um sicherzustellen, dass die Daten den höchsten Standards entsprechen und nicht nur im Labor, sondern auch in der Praxis wie gewünscht funktionieren.
4. Eine beschleunigte Entwicklungszeitleiste
Die KI-Entwicklung geschieht nicht über Nacht, aber sie kann schneller gehen, wenn Sie mit Shaip zusammenarbeiten. Die interne Datenerfassung und Annotation führt zu einem erheblichen betrieblichen Engpass, der den Rest des Entwicklungsprozesses aufhält. Durch die Zusammenarbeit mit Shaip haben Sie sofortigen Zugriff auf unsere umfangreiche Bibliothek mit gebrauchsfertigen Daten, und unsere Experten können mit unserem fundierten Branchenwissen und unserem globalen Netzwerk jede Art von zusätzlichem Input beschaffen, den Sie benötigen. Ohne die Belastung durch Sourcing und Anmerkungen kann Ihr Team sofort mit der eigentlichen Entwicklung beginnen, und unser Schulungsmodell kann dabei helfen, frühzeitig Ungenauigkeiten zu erkennen, um die zum Erreichen der Genauigkeitsziele erforderlichen Iterationen zu reduzieren.
Wenn Sie nicht bereit sind, alle Aspekte Ihres Datenmanagements auszulagern, bietet Shaip auch eine Cloud-basierte Plattform, die Teams hilft, verschiedene Arten von Daten effizienter zu produzieren, zu ändern und zu kommentieren, einschließlich Unterstützung für Bilder, Video, Text und Audio . ShaipCloud umfasst eine Vielzahl intuitiver Validierungs- und Workflow-Tools, wie eine patentierte Lösung zum Verfolgen und Überwachen von Arbeitslasten, ein Transkriptionstool zum Transkribieren komplexer und schwieriger Audioaufnahmen und eine Qualitätskontrollkomponente, um eine kompromisslose Qualität zu gewährleisten. Das Beste daran ist, dass es skalierbar ist, sodass es mit den unterschiedlichen Anforderungen Ihres Projekts mitwachsen kann.
Das Zeitalter der KI-Innovation steht erst am Anfang und wir werden in den kommenden Jahren unglaubliche Fortschritte und Innovationen erleben, die das Potenzial haben, ganze Branchen oder sogar die Gesellschaft insgesamt umzugestalten. Bei Shaip möchten wir unsere Expertise nutzen, um als transformative Kraft zu dienen und den revolutionärsten Unternehmen der Welt zu helfen, die Leistungsfähigkeit von KI-Lösungen zu nutzen, um ehrgeizige Ziele zu erreichen.
Wir verfügen über umfassende Erfahrung in Gesundheitsanwendungen und dialogorientierter KI, verfügen aber auch über die notwendigen Fähigkeiten, um Modelle für fast jede Art von Anwendung zu trainieren. Für weitere Informationen darüber, wie Shaip Ihr Projekt von der Idee bis zur Umsetzung unterstützen kann, werfen Sie einen Blick auf die vielen Ressourcen auf unserer Website oder kontaktieren Sie uns noch heute.
