
KI, Big Data und maschinelles Lernen beeinflussen weiterhin politische Entscheidungsträger, Unternehmen, Wissenschaft, Medienhäuser und eine Vielzahl von Branchen auf der ganzen Welt. Berichte deuten darauf hin, dass die weltweite Adoptionsrate von KI derzeit bei liegt 35% in 2022 – eine satte Steigerung von 4 % gegenüber 2021. Weitere 42 % der Unternehmen untersuchen Berichten zufolge die vielen Vorteile von KI für ihr Geschäft.
Unterstützung der vielen KI-Initiativen und Maschinelles lernen Lösungen sind Daten. KI kann nur so gut sein wie die Daten, die den Algorithmus füttern. Daten von geringer Qualität könnten zu Ergebnissen von geringer Qualität und ungenauen Vorhersagen führen.
Während der Entwicklung von ML- und KI-Lösungen viel Aufmerksamkeit geschenkt wurde, fehlt das Bewusstsein dafür, was sich als Qualitätsdatensatz qualifiziert. In diesem Artikel navigieren wir durch die Zeitachse von hochwertige KI-Trainingsdaten und identifizieren Sie die Zukunft der KI durch ein Verständnis der Datenerfassung und des Trainings.
Definition von KI-Trainingsdaten
Beim Aufbau einer ML-Lösung kommt es auf die Quantität und Qualität des Trainingsdatensatzes an. Das ML-System benötigt nicht nur große Mengen an dynamischen, unvoreingenommenen und wertvollen Trainingsdaten, sondern auch viele davon.
Aber was sind KI-Trainingsdaten?
KI-Trainingsdaten sind eine Sammlung gekennzeichneter Daten, die zum Trainieren des ML-Algorithmus verwendet werden, um genaue Vorhersagen zu treffen. Das ML-System versucht, Muster zu erkennen und zu identifizieren, Beziehungen zwischen Parametern zu verstehen, notwendige Entscheidungen zu treffen und basierend auf den Trainingsdaten zu bewerten.
Nehmen Sie zum Beispiel das Beispiel selbstfahrender Autos. Der Trainingsdatensatz für ein selbstfahrendes ML-Modell sollte beschriftete Bilder und Videos von Autos, Fußgängern, Straßenschildern und anderen Fahrzeugen enthalten.
Kurz gesagt, um die Qualität des ML-Algorithmus zu verbessern, benötigen Sie große Mengen an gut strukturierten, kommentierten und gekennzeichneten Trainingsdaten.
Bedeutung qualitativ hochwertiger Trainingsdaten und ihre Entwicklung
Qualitativ hochwertige Trainingsdaten sind der wichtigste Input bei der Entwicklung von KI- und ML-Apps. Daten werden aus verschiedenen Quellen gesammelt und in einer unorganisierten Form präsentiert, die für maschinelles Lernen ungeeignet ist. Qualitativ hochwertige Trainingsdaten – beschriftet, kommentiert und getaggt – liegen immer in einem organisierten Format vor – ideal für ML-Training.
Qualitativ hochwertige Trainingsdaten erleichtern es dem ML-System, Objekte zu erkennen und sie nach vorgegebenen Merkmalen zu klassifizieren. Der Datensatz könnte zu schlechten Modellergebnissen führen, wenn die Klassifizierung nicht genau ist.
Die Anfänge der KI-Trainingsdaten
Obwohl KI die gegenwärtige Geschäfts- und Forschungswelt dominiert, dominierten die frühen Tage vor ML Artificial Intelligence war ganz anders.
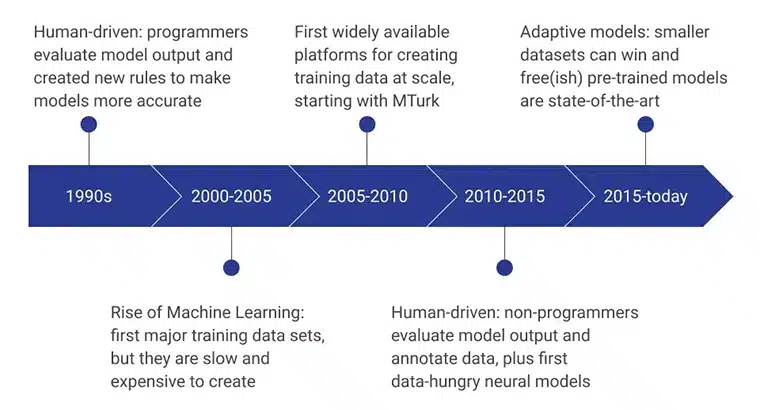
Die Anfangsphasen der KI-Trainingsdaten wurden von menschlichen Programmierern unterstützt, die die Modellausgabe bewerteten, indem sie konsequent neue Regeln entwickelten, die das Modell effizienter machten. In der Zeit von 2000 bis 2005 wurde der erste große Datensatz erstellt, und es war ein extrem langsamer, ressourcenintensiver und teurer Prozess. Dies führte dazu, dass Trainingsdatensätze in großem Maßstab entwickelt wurden, und MTurk von Amazon spielte eine bedeutende Rolle bei der Veränderung der Wahrnehmung der Menschen in Bezug auf die Datenerfassung. Gleichzeitig nahm auch die menschliche Kennzeichnung und Annotation Fahrt auf.
Die nächsten Jahre konzentrierten sich darauf, dass Nicht-Programmierer die Datenmodelle erstellten und auswerteten. Derzeit liegt der Schwerpunkt auf vortrainierten Modellen, die mit fortschrittlichen Methoden der Trainingsdatenerhebung entwickelt wurden.
Quantität über Qualität
Bei der Bewertung der Integrität von KI-Trainingsdatensätzen konzentrierten sich Datenwissenschaftler damals auf KI-Trainingsdatenmenge über Qualität.
Beispielsweise gab es ein weit verbreitetes Missverständnis, dass große Datenbanken genaue Ergebnisse liefern. Die schiere Menge an Daten galt als guter Indikator für den Wert von Daten. Die Quantität ist nur einer der Hauptfaktoren, die den Wert des Datensatzes bestimmen – die Rolle der Datenqualität wurde erkannt.
Das Bewusstsein, dass Datenqualität abhängig von Daten Vollständigkeit, Zuverlässigkeit, Gültigkeit, Verfügbarkeit und Aktualität erhöht. Am wichtigsten war, dass die Eignung der Daten für das Projekt die Qualität der gesammelten Daten bestimmte.
Einschränkungen früher KI-Systeme aufgrund schlechter Trainingsdaten
Schlechte Trainingsdaten in Verbindung mit dem Mangel an fortschrittlichen Computersystemen waren einer der Gründe für mehrere unerfüllte Versprechen früher KI-Systeme.
Aufgrund des Mangels an qualitativ hochwertigen Trainingsdaten konnten ML-Lösungen visuelle Muster, die die Entwicklung der neuronalen Forschung zum Stillstand bringen, nicht genau identifizieren. Obwohl viele Forscher das Versprechen der Erkennung gesprochener Sprache identifizierten, konnte die Forschung oder Entwicklung von Spracherkennungswerkzeugen aufgrund des Mangels an Sprachdatensätzen nicht zum Tragen kommen. Ein weiteres großes Hindernis für die Entwicklung von High-End-KI-Tools war der Mangel an Rechen- und Speicherkapazitäten der Computer.
Die Umstellung auf hochwertige Trainingsdaten
Das Bewusstsein, dass es auf die Qualität des Datensatzes ankommt, hat sich deutlich gewandelt. Damit das ML-System die menschliche Intelligenz und Entscheidungsfähigkeit genau nachahmen kann, muss es auf umfangreichen, qualitativ hochwertigen Trainingsdaten basieren.
Stellen Sie sich Ihre ML-Daten als Umfrage vor – je größer die Datenprobe Größe, desto besser die Vorhersage. Wenn die Beispieldaten nicht alle Variablen enthalten, werden Muster möglicherweise nicht erkannt oder ungenaue Schlussfolgerungen gezogen.
Fortschritte in der KI-Technologie und die Notwendigkeit besserer Trainingsdaten
 Die Fortschritte in der KI-Technologie erhöhen den Bedarf an qualitativ hochwertigen Trainingsdaten.
Die Fortschritte in der KI-Technologie erhöhen den Bedarf an qualitativ hochwertigen Trainingsdaten.Das Verständnis, dass bessere Trainingsdaten die Chance auf zuverlässige ML-Modelle erhöhen, führte zu besseren Datenerfassungs-, Annotations- und Kennzeichnungsmethoden. Die Qualität und Relevanz der Daten wirkte sich direkt auf die Qualität des KI-Modells aus.
 Die Fortschritte in der KI-Technologie erhöhen den Bedarf an qualitativ hochwertigen Trainingsdaten.
Die Fortschritte in der KI-Technologie erhöhen den Bedarf an qualitativ hochwertigen Trainingsdaten.Verstärkter Fokus auf Datenqualität und Genauigkeit
Damit das ML-Modell genaue Ergebnisse liefern kann, wird es mit hochwertigen Datensätzen gespeist, die iterative Datenverfeinerungsschritte durchlaufen.
Beispielsweise kann ein Mensch eine bestimmte Hunderasse innerhalb weniger Tage nach der Einführung in die Rasse erkennen – anhand von Bildern, Videos oder persönlich. Menschen schöpfen aus ihrer Erfahrung und den damit verbundenen Informationen, um sich dieses Wissen zu merken und es bei Bedarf abzurufen. Für eine Maschine funktioniert es jedoch nicht so einfach. Die Maschine muss mit deutlich kommentierten und beschrifteten Bildern – Hunderten oder Tausenden – dieser bestimmten Rasse und anderer Rassen gefüttert werden, damit sie die Verbindung herstellen kann.
Ein KI-Modell sagt das Ergebnis voraus, indem es die trainierten Informationen mit den in der präsentierten Informationen korreliert realen Welt. Der Algorithmus wird nutzlos, wenn die Trainingsdaten keine relevanten Informationen enthalten.
Bedeutung diverser und repräsentativer Trainingsdaten
Eine erhöhte Datenvielfalt erhöht auch die Kompetenz, reduziert Vorurteile und fördert die gerechte Darstellung aller Szenarien. Wenn das KI-Modell mit einem homogenen Datensatz trainiert wird, können Sie sicher sein, dass die neue Anwendung nur für einen bestimmten Zweck funktioniert und einer bestimmten Bevölkerung dient.Ein Datensatz könnte in Bezug auf eine bestimmte Population, Rasse, Geschlecht, Wahl und intellektuelle Meinungen voreingenommen sein, was zu einem ungenauen Modell führen könnte.
Es ist wichtig sicherzustellen, dass der gesamte Prozessablauf der Datenerhebung, einschließlich der Auswahl des Themenpools, der Kuration, Annotation und Kennzeichnung, angemessen vielfältig, ausgewogen und repräsentativ für die Bevölkerung ist.
 Eine erhöhte Datenvielfalt erhöht auch die Kompetenz, reduziert Vorurteile und fördert die gerechte Darstellung aller Szenarien. Wenn das KI-Modell mit einem homogenen Datensatz trainiert wird, können Sie sicher sein, dass die neue Anwendung nur für einen bestimmten Zweck funktioniert und einer bestimmten Bevölkerung dient.
Eine erhöhte Datenvielfalt erhöht auch die Kompetenz, reduziert Vorurteile und fördert die gerechte Darstellung aller Szenarien. Wenn das KI-Modell mit einem homogenen Datensatz trainiert wird, können Sie sicher sein, dass die neue Anwendung nur für einen bestimmten Zweck funktioniert und einer bestimmten Bevölkerung dient.Die Zukunft der KI-Trainingsdaten
Der zukünftige Erfolg von KI-Modellen hängt von der Qualität und Quantität der Trainingsdaten ab, die zum Trainieren der ML-Algorithmen verwendet werden. Es ist wichtig zu erkennen, dass diese Beziehung zwischen Datenqualität und -quantität aufgabenspezifisch ist und keine eindeutige Antwort hat.
Letztendlich wird die Angemessenheit eines Trainingsdatensatzes durch seine Fähigkeit definiert, für den Zweck, für den er erstellt wurde, zuverlässig gute Leistungen zu erbringen.
Fortschritte bei der Datenerfassung und Annotationstechniken
Da ML empfindlich auf die zugeführten Daten reagiert, ist es wichtig, die Datenerfassungs- und Anmerkungsrichtlinien zu rationalisieren. Fehler bei der Datenerfassung, Kuration, falsche Darstellung, unvollständige Messungen, ungenaue Inhalte, Datenduplizierung und fehlerhafte Messungen tragen zu einer unzureichenden Datenqualität bei.
Die automatisierte Datenerfassung durch Data Mining, Web Scraping und Datenextraktion ebnet den Weg für eine schnellere Datengenerierung. Darüber hinaus fungieren vorgefertigte Datensätze als Quick-Fix-Datenerfassungstechnik.
Crowdsourcing ist eine weitere wegweisende Methode der Datenerhebung. Obwohl die Richtigkeit der Daten nicht garantiert werden kann, sind sie ein hervorragendes Werkzeug, um ein öffentliches Image zu sammeln. Endlich spezialisiert Datensammlung Experten stellen auch zweckgebundene Daten zur Verfügung.
Stärkere Betonung ethischer Erwägungen bei Trainingsdaten
Mit den schnellen Fortschritten in der KI sind mehrere ethische Probleme aufgetaucht, insbesondere bei der Erfassung von Trainingsdaten. Einige ethische Erwägungen bei der Erhebung von Trainingsdaten umfassen Einwilligung nach Aufklärung, Transparenz, Voreingenommenheit und Datenschutz.Da Daten heute alles von Gesichtsbildern, Fingerabdrücken, Sprachaufzeichnungen und anderen kritischen biometrischen Daten umfassen, wird es immer wichtiger, die Einhaltung rechtlicher und ethischer Praktiken sicherzustellen, um teure Gerichtsverfahren und Rufschädigung zu vermeiden.
Das Potenzial für noch bessere Qualität und vielfältigere Trainingsdaten in der Zukunft
Es gibt ein riesiges Potenzial für hochwertige und vielfältige Trainingsdaten in der Zukunft. Dank des Bewusstseins für Datenqualität und der Verfügbarkeit von Datenanbietern, die den Qualitätsansprüchen von KI-Lösungen gerecht werden.
Derzeitige Datenanbieter sind in der Lage, bahnbrechende Technologien einzusetzen, um auf ethische und legale Weise riesige Mengen verschiedener Datensätze zu beschaffen. Sie haben auch interne Teams, um die Daten zu kennzeichnen, zu kommentieren und zu präsentieren, die für verschiedene ML-Projekte angepasst sind.
 Mit den schnellen Fortschritten in der KI sind mehrere ethische Probleme aufgetaucht, insbesondere bei der Erfassung von Trainingsdaten. Einige ethische Erwägungen bei der Erhebung von Trainingsdaten umfassen Einwilligung nach Aufklärung, Transparenz, Voreingenommenheit und Datenschutz.
Mit den schnellen Fortschritten in der KI sind mehrere ethische Probleme aufgetaucht, insbesondere bei der Erfassung von Trainingsdaten. Einige ethische Erwägungen bei der Erhebung von Trainingsdaten umfassen Einwilligung nach Aufklärung, Transparenz, Voreingenommenheit und Datenschutz.Zusammenfassung
Es ist wichtig, mit zuverlässigen Anbietern zusammenzuarbeiten, die über ein ausgeprägtes Verständnis von Daten und Qualität verfügen Entwicklung von High-End-KI-Modellen. Shaip ist das führende Annotationsunternehmen, das in der Lage ist, kundenspezifische Datenlösungen bereitzustellen, die die Anforderungen und Ziele Ihres KI-Projekts erfüllen. Arbeiten Sie mit uns zusammen und erkunden Sie die Kompetenzen, das Engagement und die Zusammenarbeit, die wir mitbringen.


