
Künstliche Intelligenz fördert menschenähnliche Interaktionen mit Computersystemen, während maschinelles Lernen es diesen Maschinen ermöglicht, bei jeder Interaktion zu lernen, menschliche Intelligenz nachzuahmen. Aber was treibt diese hochentwickelten ML- und KI-Tools an? Datenanmerkung.
Daten sind der Rohstoff für ML-Algorithmen – je mehr Daten Sie verwenden, desto besser wird das KI-Produkt. Der Zugriff auf große Datenmengen ist zwar von entscheidender Bedeutung, es ist jedoch ebenso wichtig, sicherzustellen, dass sie genau kommentiert sind, um praktikable Ergebnisse zu erzielen. Die Datenannotation ist das Datenkraftwerk hinter der fortschrittlichen, zuverlässigen und genauen ML-Algorithmusleistung.
Rolle der Datenannotation im KI-Training
Die Datenannotation spielt eine Schlüsselrolle in der ML-Schulung und dem Gesamterfolg von KI-Projekten. Es hilft bei der Identifizierung bestimmter Bilder, Daten, Ziele und Videos und beschriftet sie, um es der Maschine zu erleichtern, Muster zu erkennen und Daten zu klassifizieren. Es ist eine von Menschen geführte Aufgabe, die das ML-Modell trainiert, um genaue Vorhersagen zu treffen.
Wenn die Datenannotation nicht genau durchgeführt wird, kann der ML-Algorithmus Attribute nicht einfach Objekten zuordnen.
Bedeutung annotierter Trainingsdaten für KI-Systeme
Die Datenannotation ermöglicht das genaue Funktionieren von ML-Modellen. Es besteht ein unbestreitbarer Zusammenhang zwischen der Genauigkeit und Präzision der Datenannotation und dem Erfolg des KI-Projekts.
Der globale KI-Marktwert, der im Jahr 119 auf 2022 Milliarden US-Dollar geschätzt wird, wird voraussichtlich erreicht werden $ 1,597 Milliarden 2030, das während des Zeitraums mit einer CAGR von 38 % gewachsen ist. Während das gesamte KI-Projekt mehrere kritische Schritte durchläuft, befindet sich Ihr Projekt in der Phase der Datenanmerkung in der wichtigsten Phase.
Das Sammeln von Daten um der Daten willen wird Ihrem Projekt nicht viel helfen. Sie benötigen riesige Mengen hochwertiger und relevanter Daten, um Ihr KI-Projekt erfolgreich umzusetzen. Ungefähr 80 % Ihrer Zeit in der ML-Projektentwicklung verbringen Sie mit datenbezogenen Aufgaben wie Labeling, Scrubbing, Aggregieren, Identifizieren, Erweitern und Kommentieren.
Die Annotation von Daten ist ein Bereich, in dem Menschen gegenüber Computern einen Vorteil haben, da wir die angeborene Fähigkeit haben, Absichten zu entschlüsseln, Mehrdeutigkeiten zu überwinden und unsichere Informationen zu klassifizieren.
Warum ist Datenanmerkung wichtig?
Der Wert und die Glaubwürdigkeit Ihrer Lösung für künstliche Intelligenz hängen weitgehend von der Qualität der Dateneingabe ab, die für das Modelltraining verwendet wird.
Eine Maschine kann Bilder nicht so verarbeiten wie wir; sie müssen trainiert werden, Muster durch Training zu erkennen. Da maschinelle Lernmodelle für eine Vielzahl von Anwendungen geeignet sind – kritische Lösungen wie das Gesundheitswesen und autonome Fahrzeuge –, bei denen jeder Fehler in der Datenannotation gefährliche Auswirkungen haben kann.
Die Datenannotation stellt sicher, dass Ihre KI-Lösung ihre volle Leistungsfähigkeit ausschöpft. Das Trainieren eines ML-Modells, um seine Umgebung durch Muster und Korrelationen genau zu interpretieren, Vorhersagen zu treffen und die erforderlichen Maßnahmen zu ergreifen, erfordert eine hohe Kategorisierung und Kommentierung Trainingsdaten. Die Anmerkung zeigt dem ML-Modell die erforderliche Vorhersage durch Markieren, Transkribieren und Beschriften kritischer Merkmale im Datensatz.
Überwachtes Lernen
Bevor wir uns eingehender mit der Datenannotation befassen, lassen Sie uns die Datenannotation durch überwachtes und nicht überwachtes Lernen enträtseln.
Eine Unterkategorie des maschinellen Lernens, des überwachten maschinellen Lernens, weist auf das Training von KI-Modellen mit Hilfe eines gut gekennzeichneten Datensatzes hin. Bei einer überwachten Lernmethode sind einige Daten bereits genau gekennzeichnet und kommentiert. Wenn das ML-Modell neuen Daten ausgesetzt wird, verwendet es die Trainingsdaten, um auf der Grundlage der gekennzeichneten Daten eine genaue Vorhersage zu treffen.
Zum Beispiel wird das ML-Modell auf einem Schrank voller verschiedener Arten von Kleidung trainiert. Der erste Trainingsschritt besteht darin, das Modell mit verschiedenen Arten von Kleidungsstücken zu trainieren, wobei die Eigenschaften und Attribute jedes Kleidungsstücks verwendet werden. Nach dem Training wird die Maschine in der Lage sein, einzelne Kleidungsstücke zu identifizieren, indem sie ihr Vorwissen oder Training anwendet. Überwachtes Lernen kann in Klassifikation (basierend auf Kategorie) und Regression (basierend auf realem Wert) kategorisiert werden.
Wie Datenannotation die Leistung von KI-Systemen beeinflusst
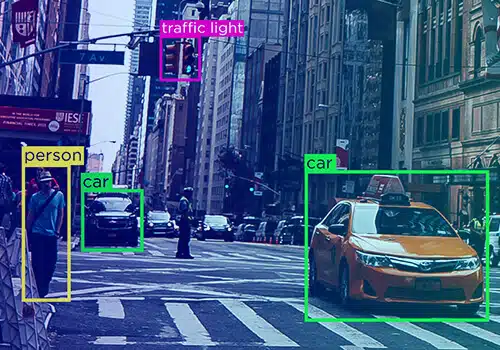 Daten sind nie eine Einheit – sie nehmen verschiedene Formen an – Text, Video und Bild. Es erübrigt sich zu erwähnen, dass Datenannotationen in verschiedenen Formen vorliegen.
Daten sind nie eine Einheit – sie nehmen verschiedene Formen an – Text, Video und Bild. Es erübrigt sich zu erwähnen, dass Datenannotationen in verschiedenen Formen vorliegen.
Damit die Maschine verschiedene Entitäten verstehen und genau identifizieren kann, ist es wichtig, die Qualität des Named Entity Tagging hervorzuheben. Ein Fehler beim Taggen und Kommentieren, und die ML konnte Amazon nicht mehr unterscheiden – den E-Commerce-Shop, den Fluss oder einen Papagei.
Außerdem hilft die Datenannotation Maschinen dabei, subtile Absichten zu erkennen – eine Eigenschaft, die für Menschen natürlich ist. Wir kommunizieren anders, und Menschen verstehen sowohl explizit ausgedrückte Gedanken als auch implizite Botschaften. Beispielsweise können Antworten oder Rezensionen in sozialen Medien sowohl positiv als auch negativ sein, und das ML sollte in der Lage sein, beides zu verstehen. 'Guter Platz. Werde wiederkommen.' Es ist ein positiver Satz, während „Was für ein großartiger Ort es früher war! Früher haben wir diesen Ort geliebt!' ist negativ, und menschliche Anmerkungen können diesen Prozess viel einfacher machen.

Herausforderungen bei der Datenannotation und wie man sie überwindet
Zwei Hauptherausforderungen bei der Datenannotation sind Kosten und Genauigkeit.
Der Bedarf an hochgenauen Daten: Das Schicksal von KI- und ML-Projekten hängt von der Qualität der annotierten Daten ab. Die ML- und KI-Modelle müssen konsistent mit gut klassifizierten Daten gefüttert werden, die das Modell trainieren können, um die Korrelation zwischen Variablen zu erkennen.
Der Bedarf an großen Datenmengen: Alle ML- und KI-Modelle gedeihen auf großen Datensätzen – ein einzelnes ML-Projekt benötigt mindestens Tausende von beschrifteten Elementen.
Der Bedarf an Ressourcen: KI-Projekte sind ressourcenabhängig, sowohl in Bezug auf Kosten, Zeit und Personal. Ohne beides könnte die Qualität Ihres Datenannotationsprojekts durcheinander geraten.
[Lesen Sie auch: Videoanmerkung für maschinelles Lernen ]
Best Practices in der Datenannotation
Der Wert der Datenannotation zeigt sich in ihrer Auswirkung auf das Ergebnis des KI-Projekts. Wenn der Datensatz, mit dem Sie Ihre ML-Modelle trainieren, voller Inkonsistenzen, voreingenommen, unausgeglichen oder beschädigt ist, könnte Ihre KI-Lösung versagen. Wenn die Beschriftungen falsch und die Anmerkungen inkonsistent sind, führt auch die KI-Lösung zu ungenauen Vorhersagen. Was sind also die Best Practices für die Datenannotation?
Tipps für eine effiziente und effektive Datenannotation
- Stellen Sie sicher, dass die von Ihnen erstellten Datenetiketten spezifisch und konsistent mit den Projektanforderungen sind und dennoch allgemein genug, um alle möglichen Variationen abzudecken.
- Kommentieren Sie große Datenmengen, die zum Trainieren des maschinellen Lernmodells erforderlich sind. Je mehr Daten Sie kommentieren, desto besser ist das Ergebnis des Modelltrainings.
- Datenannotationsrichtlinien tragen wesentlich dazu bei, Qualitätsstandards festzulegen und die Konsistenz während des gesamten Projekts und über mehrere Annotatoren hinweg sicherzustellen.
- Da die Annotation von Daten kostspielig und arbeitsintensiv sein kann, ist es sinnvoll, vorbeschriftete Datensätze von Dienstleistern zu prüfen.
- Um eine genaue Datenannotation und Schulung zu unterstützen, nutzen Sie die Effizienz von Human-in-the-Loop, um Vielfalt zu schaffen und mit kritischen Fällen zusammen mit den Funktionen von Annotationssoftware umzugehen.
- Priorisieren Sie die Qualität, indem Sie die Annotatoren auf Qualitätskonformität, Genauigkeit und Konsistenz testen.
Bedeutung der Qualitätskontrolle im Annotationsprozess
 Qualitativ hochwertige Datenanmerkungen sind das Lebenselixier leistungsstarker KI-Lösungen. Gut kommentierte Datensätze helfen KI-Systemen, selbst in einer chaotischen Umgebung einwandfrei zu funktionieren. Ebenso gilt auch das Umgekehrte. Ein Datensatz voller Annotationsungenauigkeiten wird zu inkonsistenten Lösungen führen.
Qualitativ hochwertige Datenanmerkungen sind das Lebenselixier leistungsstarker KI-Lösungen. Gut kommentierte Datensätze helfen KI-Systemen, selbst in einer chaotischen Umgebung einwandfrei zu funktionieren. Ebenso gilt auch das Umgekehrte. Ein Datensatz voller Annotationsungenauigkeiten wird zu inkonsistenten Lösungen führen.
Daher spielt die Qualitätskontrolle im Bild-, Videokennzeichnungs- und Anmerkungsprozess eine wichtige Rolle für das KI-Ergebnis. Die Aufrechterhaltung hoher Qualitätskontrollstandards während des gesamten Annotationsprozesses ist jedoch für kleine und große Unternehmen eine Herausforderung. Die Abhängigkeit von verschiedenen Arten von Anmerkungswerkzeugen und unterschiedlichem Anmerkungspersonal kann schwer zu beurteilen und die Qualitätskonsistenz aufrechtzuerhalten.
Die Aufrechterhaltung der Qualität von verteilten oder remote arbeitenden Datenannotierern ist schwierig, insbesondere für diejenigen, die mit den erforderlichen Standards nicht vertraut sind. Darüber hinaus kann die Fehlerbehebung oder Fehlerbehebung einige Zeit in Anspruch nehmen, da sie von einer verteilten Belegschaft identifiziert werden muss.
Die Lösung wäre, die Kommentatoren zu schulen, einen Supervisor einzubeziehen oder mehrere Datenkommentatoren zu veranlassen, Peers auf Genauigkeit der Datensatzkommentierung zu prüfen und zu überprüfen. Schließlich regelmäßiges Testen der Kommentatoren hinsichtlich ihres Wissens über die Standards.
Die Rolle von Annotatoren und wie Sie die richtigen Annotatoren für Ihre Daten auswählen
Menschliche Kommentatoren sind der Schlüssel zu einem erfolgreichen KI-Projekt. Datenannotierer stellen sicher, dass die Daten genau, konsistent und zuverlässig kommentiert werden, da sie Kontext bereitstellen, die Absicht verstehen und die Grundlage für Grundwahrheiten in den Daten legen können.
Einige Daten werden mit Hilfe von Automatisierungslösungen mit ziemlicher Zuverlässigkeit künstlich oder automatisch annotiert. Sie können beispielsweise Hunderttausende Bilder von Häusern von Google herunterladen und als Datensatz erstellen. Die Genauigkeit des Datensatzes kann jedoch erst zuverlässig bestimmt werden, nachdem das Modell mit seiner Leistung begonnen hat.
Automatisierte Automatisierung könnte Dinge einfacher und schneller machen, aber unbestreitbar weniger genau. Auf der anderen Seite kann ein menschlicher Annotator langsamer und teurer sein, aber er ist genauer.
Annotatoren für menschliche Daten können Daten basierend auf ihrer Fachkompetenz, ihrem angeborenen Wissen und ihrer spezifischen Ausbildung kommentieren und klassifizieren. Datenannotatoren stellen Genauigkeit, Präzision und Konsistenz her.
[Lesen Sie auch: Ein Leitfaden für Anfänger zur Datenannotation: Tipps und Best Practices ]
Zusammenfassung
Um ein leistungsstarkes KI-Projekt zu erstellen, benötigen Sie qualitativ hochwertige kommentierte Trainingsdaten. Während die konsistente Erfassung gut kommentierter Daten selbst für große Unternehmen zeit- und ressourcenintensiv sein kann, liegt die Lösung darin, die Dienste etablierter Anbieter von Datenanmerkungsdiensten wie Shaip in Anspruch zu nehmen. Bei Shaip helfen wir Ihnen, Ihre KI-Fähigkeiten durch unsere spezialisierten Dienste zur Datenannotation zu skalieren, indem wir die Markt- und Kundenanforderungen erfüllen.


