
Automatische Spracherkennungssysteme und virtuelle Assistenten wie Siri, Alexa und Cortana sind zu alltäglichen Bestandteilen unseres Lebens geworden. Unsere Abhängigkeit von ihnen nimmt erheblich zu, je klüger sie werden. Vom Einschalten unseres Lichts über das Telefonieren bis hin zum Wechseln des Fernsehkanals nutzen wir diese intelligenten Technologien, um alltägliche Aufgaben zu erledigen.
Haben Sie sich jedoch jemals gefragt, wie diese Spracherkennungssysteme funktionieren?
Nun, dieser Blog wird Sie über einige der Grundlagen der automatischen Spracherkennung informieren. Außerdem werden wir seine Funktionsweise und den Aufbau funktionaler virtueller Assistenten wie Siri untersuchen.
Was ist automatische Spracherkennung?
Automatic Speech Recognition (ASR) ist eine Software, die es dem Computersystem ermöglicht, menschliche Sprache in Text umzuwandeln, indem mehrere Algorithmen für künstliche Intelligenz und maschinelles Lernen genutzt werden.
Nach dem Umwandeln und Analysieren des gegebenen Befehls antwortet der Computer mit einer entsprechenden Ausgabe für den Benutzer. ASR wurde erstmals 1962 eingeführt und hat seitdem seine Abläufe kontinuierlich verbessert und durch beliebte Anwendungen wie Alexa und Siri großes Rampenlicht erlangt.
Was ist der Prozess für die Spracherfassung zum Trainieren von ASR-Modellen?
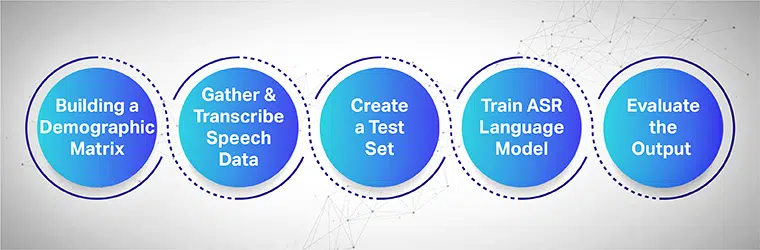
Die Sprachsammlung zielt darauf ab, mehrere Beispielaufzeichnungen aus mehreren Bereichen zu sammeln, die zum Füttern und Trainieren von ASR-Modellen verwendet werden. Das ASR-System bietet die höchste Effizienz, wenn große Sprach- und Audiodatensätze gesammelt und seinem System bereitgestellt werden.
Um nahtlos zu funktionieren, müssen die gesammelten Sprachdatensätze alle Zieldemografien, Sprachen, Akzente und Dialekte enthalten. Der folgende Prozess zeigt, wie das maschinelle Lernmodell in mehreren Schritten trainiert wird:
Beginnen Sie mit dem Aufbau einer demografischen Matrix
Sammelt in erster Linie die Daten für verschiedene demografische Merkmale wie Standort, Geschlecht, Sprache, Alter und Akzente. Stellen Sie außerdem sicher, dass Sie eine Vielzahl von Umgebungsgeräuschen wie Straßenlärm, Wartezimmerlärm, Lärm von öffentlichen Büros usw. erfassen.
Sammeln und transkribieren Sie die Sprachdaten
Der nächste Schritt ist das Sammeln menschlicher Audio- und Sprachproben basierend auf verschiedenen geografischen Standorten, um Ihr ASR-Modell zu trainieren. Es ist ein wichtiger Schritt und erfordert menschliche Experten, lange und kurze Wortäußerungen durchzuführen, um das echte Gefühl des Satzes zu bekommen und dieselben Sätze in verschiedenen Akzenten und Dialekten zu wiederholen.
Erstellen Sie eine separate Testreihe
Sobald Sie den transkribierten Text gesammelt haben, besteht der nächste Schritt darin, ihn mit entsprechenden Audiodaten zu koppeln. Dann segmentieren Sie die Daten weiter und fügen Sie eine Aussage daraus ein. Jetzt können Sie aus den segmentierten Datenpaaren zufällige Daten aus einem Satz für weitere Tests ziehen.
Trainieren Sie Ihr ASR-Sprachmodell
Je mehr Informationen Ihre Datensätze enthalten, desto besser würde Ihr KI-trainiertes Modell funktionieren. Generieren Sie daher mehrere Variationen von Text und Reden, die Sie zuvor aufgezeichnet haben. Paraphrasieren Sie dieselben Sätze mit unterschiedlichen Sprachnotationen.
Bewerten Sie die Ausgabe und iterieren Sie schließlich
Misst schließlich die Ausgabe Ihres ASR-Modells, um seine Leistung zu korrigieren. Testen Sie das Modell anhand eines Testsatzes, um seine Effizienz zu bestimmen. Binden Sie Ihr ASR-Modell in geeigneter Weise in eine Rückkopplungsschleife ein, um die gewünschte Ausgabe zu generieren und etwaige Lücken zu schließen.
[Lesen Sie auch: Ein umfassender Überblick über die automatische Spracherkennung]

Was sind die verschiedenen Anwendungsfälle der Spracherkennung?
Spracherkennungstechnologie ist heute in vielen Branchen weit verbreitet. Einige Branchen, die diese enorme Technologie einsetzen, sind wie folgt:
 Nahrungsmittelindustrie: Lebensmittelgiganten wie Wendy's und McDonald's werden ihre Kundenerlebnisse mit ASR verbessern. In vielen ihrer Filialen haben sie voll funktionsfähige ASR-Modelle eingesetzt, um Bestellungen entgegenzunehmen und sie weiter an die Kochabteilung weiterzuleiten, um die Kundenbestellung fertig zu stellen.
Nahrungsmittelindustrie: Lebensmittelgiganten wie Wendy's und McDonald's werden ihre Kundenerlebnisse mit ASR verbessern. In vielen ihrer Filialen haben sie voll funktionsfähige ASR-Modelle eingesetzt, um Bestellungen entgegenzunehmen und sie weiter an die Kochabteilung weiterzuleiten, um die Kundenbestellung fertig zu stellen.- Telekommunikation: Vodafone ist einer der größten Telekommunikationsanbieter der Welt. Es hat seine Kundenbetreuungs- und Telefonvermittlungsdienste unter Nutzung von ASR-Modellen entwickelt, die Sie bei der Lösung verschiedener Anfragen und der Weiterleitung Ihrer Anrufe an die betroffenen Abteilungen unterstützen.
- Reisen und Transport: Google Android Auto oder Apple CarPlay haben sich durchgesetzt. Die meisten Menschen verwenden sie, um Navigationssysteme zu aktivieren, Nachrichten zu senden oder Musikwiedergabelisten zu wechseln. Mit technologischen Fortschritten werden solche Systeme jedoch immer raffinierter.
Der im BMW 3er eingeführte BMW Intelligent Personal Assistant ist viel intelligenter als herkömmliche Sprachassistenten. Es kann Fahrern ermöglichen, autobezogene Informationen zu finden und das Auto mit Sprachbefehlen zu bedienen. - Medien und Unterhaltung: Auch die Medienbranche nutzt ASR in vielen ihrer Projekte. Youtube hat einen KI-basierten Assistenten gestartet, der Live-Auto-Untertitel generiert. Während Sie auf dem Bildschirm sprechen, stellt der Assistent die Untertitel bereit, um das Video einer größeren Gruppe von Youtube-Benutzern zugänglich zu machen.
 Nahrungsmittelindustrie: Lebensmittelgiganten wie Wendy's und McDonald's werden ihre Kundenerlebnisse mit ASR verbessern. In vielen ihrer Filialen haben sie voll funktionsfähige ASR-Modelle eingesetzt, um Bestellungen entgegenzunehmen und sie weiter an die Kochabteilung weiterzuleiten, um die Kundenbestellung fertig zu stellen.
Nahrungsmittelindustrie: Lebensmittelgiganten wie Wendy's und McDonald's werden ihre Kundenerlebnisse mit ASR verbessern. In vielen ihrer Filialen haben sie voll funktionsfähige ASR-Modelle eingesetzt, um Bestellungen entgegenzunehmen und sie weiter an die Kochabteilung weiterzuleiten, um die Kundenbestellung fertig zu stellen. Telekommunikation: Vodafone ist einer der größten Telekommunikationsanbieter der Welt. Es hat seine Kundenbetreuungs- und Telefonvermittlungsdienste unter Nutzung von ASR-Modellen entwickelt, die Sie bei der Lösung verschiedener Anfragen und der Weiterleitung Ihrer Anrufe an die betroffenen Abteilungen unterstützen.
Telekommunikation: Vodafone ist einer der größten Telekommunikationsanbieter der Welt. Es hat seine Kundenbetreuungs- und Telefonvermittlungsdienste unter Nutzung von ASR-Modellen entwickelt, die Sie bei der Lösung verschiedener Anfragen und der Weiterleitung Ihrer Anrufe an die betroffenen Abteilungen unterstützen. Reisen und Transport: Google Android Auto oder Apple CarPlay haben sich durchgesetzt. Die meisten Menschen verwenden sie, um Navigationssysteme zu aktivieren, Nachrichten zu senden oder Musikwiedergabelisten zu wechseln. Mit technologischen Fortschritten werden solche Systeme jedoch immer raffinierter.
Reisen und Transport: Google Android Auto oder Apple CarPlay haben sich durchgesetzt. Die meisten Menschen verwenden sie, um Navigationssysteme zu aktivieren, Nachrichten zu senden oder Musikwiedergabelisten zu wechseln. Mit technologischen Fortschritten werden solche Systeme jedoch immer raffinierter. Medien und Unterhaltung: Auch die Medienbranche nutzt ASR in vielen ihrer Projekte. Youtube hat einen KI-basierten Assistenten gestartet, der Live-Auto-Untertitel generiert. Während Sie auf dem Bildschirm sprechen, stellt der Assistent die Untertitel bereit, um das Video einer größeren Gruppe von Youtube-Benutzern zugänglich zu machen.
Medien und Unterhaltung: Auch die Medienbranche nutzt ASR in vielen ihrer Projekte. Youtube hat einen KI-basierten Assistenten gestartet, der Live-Auto-Untertitel generiert. Während Sie auf dem Bildschirm sprechen, stellt der Assistent die Untertitel bereit, um das Video einer größeren Gruppe von Youtube-Benutzern zugänglich zu machen.
[Lesen Sie auch: Was ist Speech-To-Text-Technologie und wie funktioniert sie?]
Wie kann Shaip helfen?
Shaip ist einer der führenden KI-Schulungsdienste, der über Fachwissen in mehreren Bereichen von KI und ML verfügt. Sie können Ihnen beim Aufbau Ihres eigenen Datensatzes helfen, der für verschiedene Anwendungen und Projekte verwendet werden könnte.
Einige der von Shaip angebotenen Dienstleistungen sind:
- Automatisierte Spracherkennung (ASR)
- Geskriptete Sprachsammlung
- Transkreation
- Spontane Sprachsammlung
- Redesammlung/ Weckwörter,
- Text-zu-Sprache (TTS)
Sie können diese Dienste nutzen, um die besten Ergebnisse für Ihre KI-basierten Projekte zu erzielen. Erfahren Sie mehr über diese Dienstleistungen, indem Sie sich noch heute an unser Expertenteam wenden!


